Online-Offline Colocation
Feature Introduction
With the increasing diversity of business types and hardware resources in the cloud, higher management requirements are placed on cloud-native systems, such as resource utilization and quality of service assurance. To enable mixed deployment systems with diverse workloads and computing power to run in an optimal state, various online-offline colocation solutions have emerged. The openFuyao online-offline colocation and resource overselling solution includes the following features:
- Multi-QoS hierarchical management for workloads.
- Workload-aware scheduling.
- Colocation node management.
- Colocation policy configuration.
- Node overselling resource management and reporting.
- Non-intrusive colocation Pod creation and cgroup management based on NRI mechanism.
- Multi-level system optimization with single-node colocation engine (rubik) and kernel isolation technology.
Application Scenarios
When deploying workloads, users need to determine the QoS level of the workload based on its characteristics. The scheduler will add necessary colocation information to the workload and schedule it to colocation or non-colocation nodes to meet users' mixed deployment requirements. Users can also manage colocation scheduling and colocation nodes through unified colocation configuration management.
Capability Scope
- Support priority scheduling and load-balanced scheduling for workloads with different QoS levels.
- Support QoS suppression of CPU and memory for offline workloads by online workloads on a single node.
- Support eviction and rescheduling of offline workloads based on CPU/memory watermarks on a single node.
- Support advanced colocation features such as CPU elastic throttling, asynchronous memory reclaim, memory bandwidth limitation, and PSI interference detection.
- Support colocation resource monitoring.
Highlights
- Industry-leading online-offline workload colocation and resource overselling solution. Supports mixed deployment of online/offline workloads, ensuring scheduling of online workloads during peak usage while enabling offline workloads to use oversold resources during online workload low periods, improving cluster resource utilization.
- Multi-QoS classification for workloads: online workloads (HLS high-priority core-bound online workloads, LS low-priority online workloads) and offline workloads (BE workloads using oversold resources). At the scheduling level, high-priority tasks can preempt low-priority tasks, while supporting offline workload eviction to ensure offline workloads are not preempted by high-utilization online workloads for extended periods. Single-node support for HLS online workload core binding and NUMA-aware scheduling for LS online workloads.
Usage Restrictions
This feature, NUMA-aware scheduling, and NPU Operator all use volcano version 1.9.0. If NUMA-aware scheduling is already installed or if vcscheduler.enabled or vccontroller.enabled is enabled when installing NPU Operator components, there is no need to manually install volcano again. After configuring the volcano-scheduler-configmap as described in Prerequisites in the installation section, they can be used together.
Feature Dependency
The hardware and operating system dependencies for online-offline colocation features are as follows:
Single-Node Colocation Engine (rubik)
| Feature | Hardware Dependency | OS Dependency |
|---|---|---|
| CPU Suppression | None | openEuler 22.03 LTS and above (kernel 5.10.0-60.139.0.166 and above) |
| Memory Suppression | None | openEuler 22.03 LTS and above (kernel 5.10.0-60.139.0.166 and above) |
| CPU Elastic Throttling | None | openEuler 22.03 LTS and above (kernel 5.10.0-60.139.0.166 and above) |
| PSI Interference Detection | None | openEuler 22.03 LTS and above (kernel 5.10.0-60.139.0.166 and above) |
| dynCache (Memory Bandwidth Limitation) | Physical Machine (x86/ARM) | openEuler 22.03 LTS SP3 and above (kernel 5.10.0-182.0.0.95 and above) |
| dynMemory (Asynchronous Memory Reclaim) | None | openEuler 22.03 LTS SP3 and above (kernel 5.10.0-182.0.0.95 and above) |
| Offline Workload Interference Detection and Eviction | None | None |
Colocation Scheduling
| Feature | Hardware Dependency | OS Dependency | Other Dependencies |
|---|---|---|---|
| Priority and Load-Aware Scheduling | None | None | — |
| Resource Overselling Management | None | None | containerd >= 1.7 |
| NUMA Affinity Policy | None | None | — |
| Colocation Monitoring | None | None | — |
Related Configuration File Paths
The main configuration files and paths involved during runtime for each feature are as follows:
- kubelet configuration:
/var/lib/kubelet/config.yaml - containerd configuration:
/etc/containerd/config.toml - rubik-related configuration and mount paths:
/sys/fs/cgroup//sys/fs/resctrl//etc/kubernetes/node-feature-discovery/features.d//proc/sys/vm/memcg_qos_enable/dev(only for blkio)/run/rubik(ensures only one rubik process runs on each node)
Implementation Principle
The online-offline colocation component is divided into two parts in terms of functionality and deployment:
Colocation control layer responsible for unified management of colocation components.
- Global configuration plane: Provides global colocation configuration, including enabling colocation nodes, configuring eviction watermarks for the colocation engine, and setting scheduling thresholds when the scheduler performs load-balanced scheduling.
- Admission control: Provides admission controller for colocation workloads, performs rule checks on workloads with QoS-level annotations, and adds necessary resources for colocation scheduling (scheduler, priority, affinity labels, etc.).
- Unified management of oversold resources: Receives metrics collected by the overselling resource agent, periodically updates resource usage of each node and Pods on each node to the Checkpoint CRD, and periodically updates the total oversold resources in node resources.
- REST API service: Provides REST API service for interfacing with visualization interfaces.
- Colocation monitoring: Provides unified visualization interface for colocation monitoring.
Node agent deployed as DaemonSet in the Kubernetes cluster to support resource overselling in colocation scenarios and inject fine-grained resource management policies.
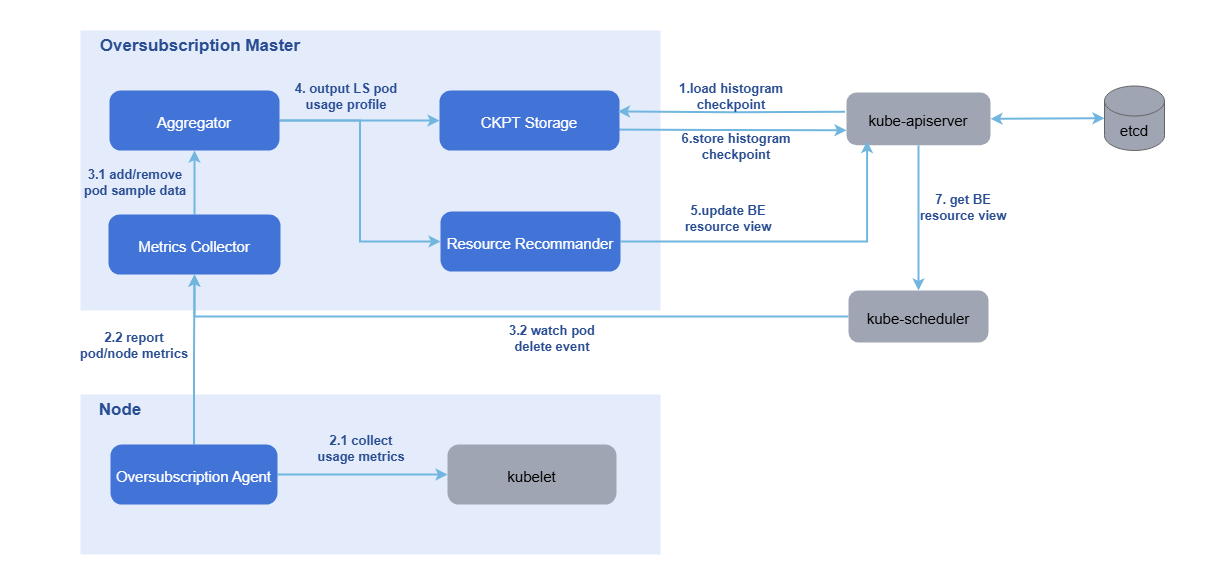
- Overselling agent: Implements resource metric collection, uses histograms to statistically predict workload resource usage details, builds application resource profiles; implements oversold resource reporting by predicting Pod actual resource usage through application resource profiles, reclaims allocated but unused resources, and reports to the unified management plane.
- Colocation agent: rubik colocation engine and additional functionality to interface with kernel APIs to enable/disable rubik features.
- Overselling resource nri plugin: Uses containerd's nri mechanism to inject fine-grained resource management policies during different lifecycle stages of containers.
Figure 1 Online-Offline Colocation and Resource Overselling Solution Example
Considering the construction of openFuyao's entire scheduling framework and for the future construction of openFuyao colocation multi-QoS classification, openFuyao introduces a three-tier QoS assurance model, subdividing online workloads into HLS (high-latency-sensitive) and LS (latency-sensitive) categories, and marking offline workloads as BE (best-effort) category, as follows:
Table 1 Three-Tier QoS Classification for Workloads
| QoS | Characteristics | Scenario | Description | K8s QoS |
|---|---|---|---|---|
| HLS (High Latency Sensitive) | Strict requirements for latency and stability. No overselling, reserved resources for better determinism. | High-demand online workloads | Corresponds to the community's Guaranteed. When node kubelet core binding is enabled, cpu cores are bound. During admission, cpu and memory request and limit are checked to ensure cpu and memory requests and limits exist and are equal, and cpu requests are integers (Core), ensuring HLS-marked Pods correspond to Guaranteed exclusive type. | Guaranteed |
| LS (Latency Sensitive) | Shared resources with better elasticity for burst traffic. | Online workloads | Typical QoS level for microservice workloads, achieving better resource elasticity and more flexible resource adjustment capabilities. | Guaranteed/Burstable |
| BE (Best Effort) | Shared resources, limited resource runtime quality, or even forcibly deleted in extreme cases. | Offline workloads | Typical QoS level for batch jobs, stable computing throughput over a period, low-cost resources, only using oversold resources. | Besteffort |
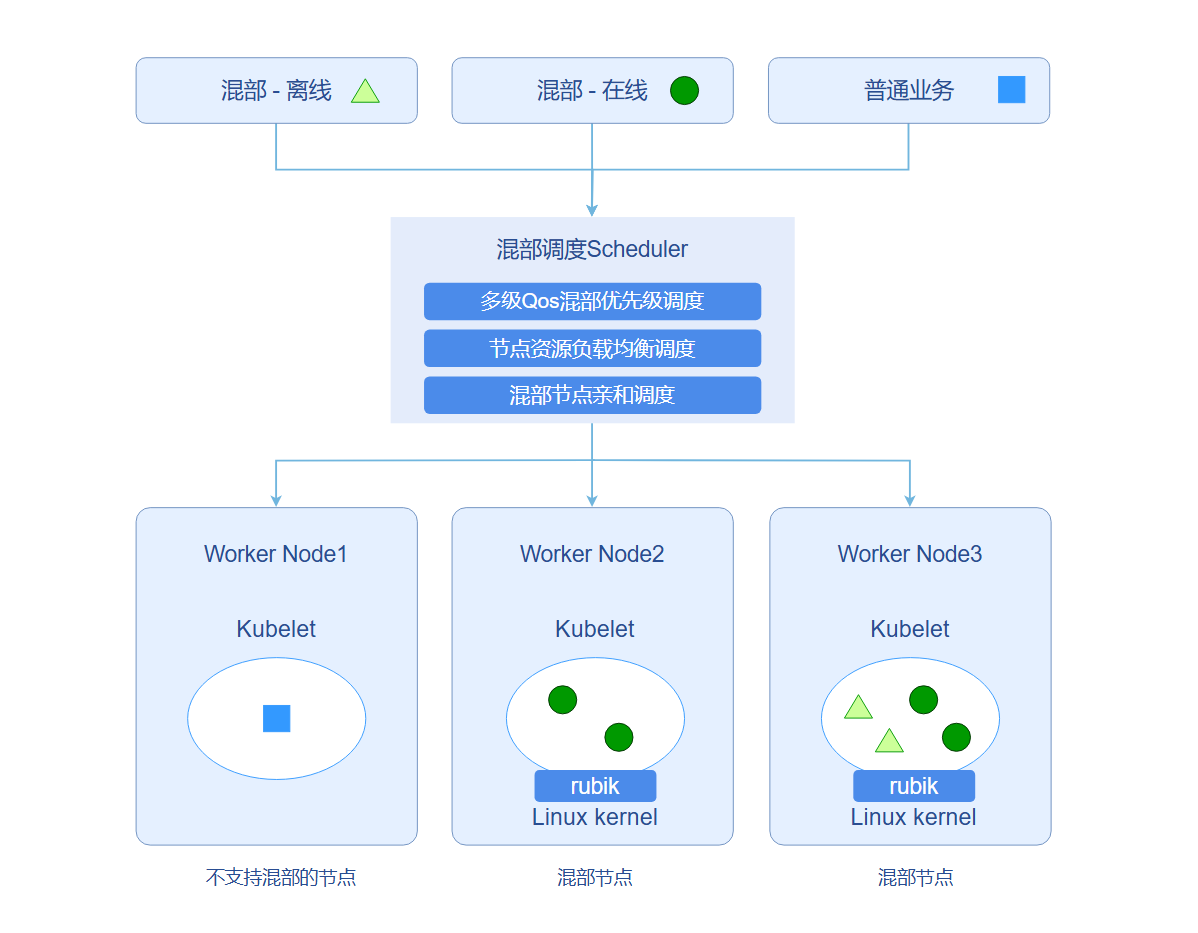
Nodes in the cluster are divided into colocation nodes and non-colocation nodes. Generally, online and offline workloads are deployed on colocation nodes, and normal workloads are deployed on non-colocation nodes. The colocation scheduler reasonably schedules the current workload to appropriate nodes based on the workload attributes to be deployed and the colocation attributes of nodes in the cluster. Workloads with different QoS levels correspond to different workload PriorityClass levels. During scheduling, the colocation scheduler performs priority scheduling/preemption at the scheduling queue level according to workload PriorityClass to ensure high-priority tasks are prioritized at the scheduling level. On the other hand, when selecting scheduling nodes, the colocation scheduler also scores each node based on the actual CPU and memory usage rates, scheduling workloads to nodes with lower combined CPU and memory usage to maximize avoidance of node overheating.
Figure 2 Online-Offline Colocation Scheduling Example
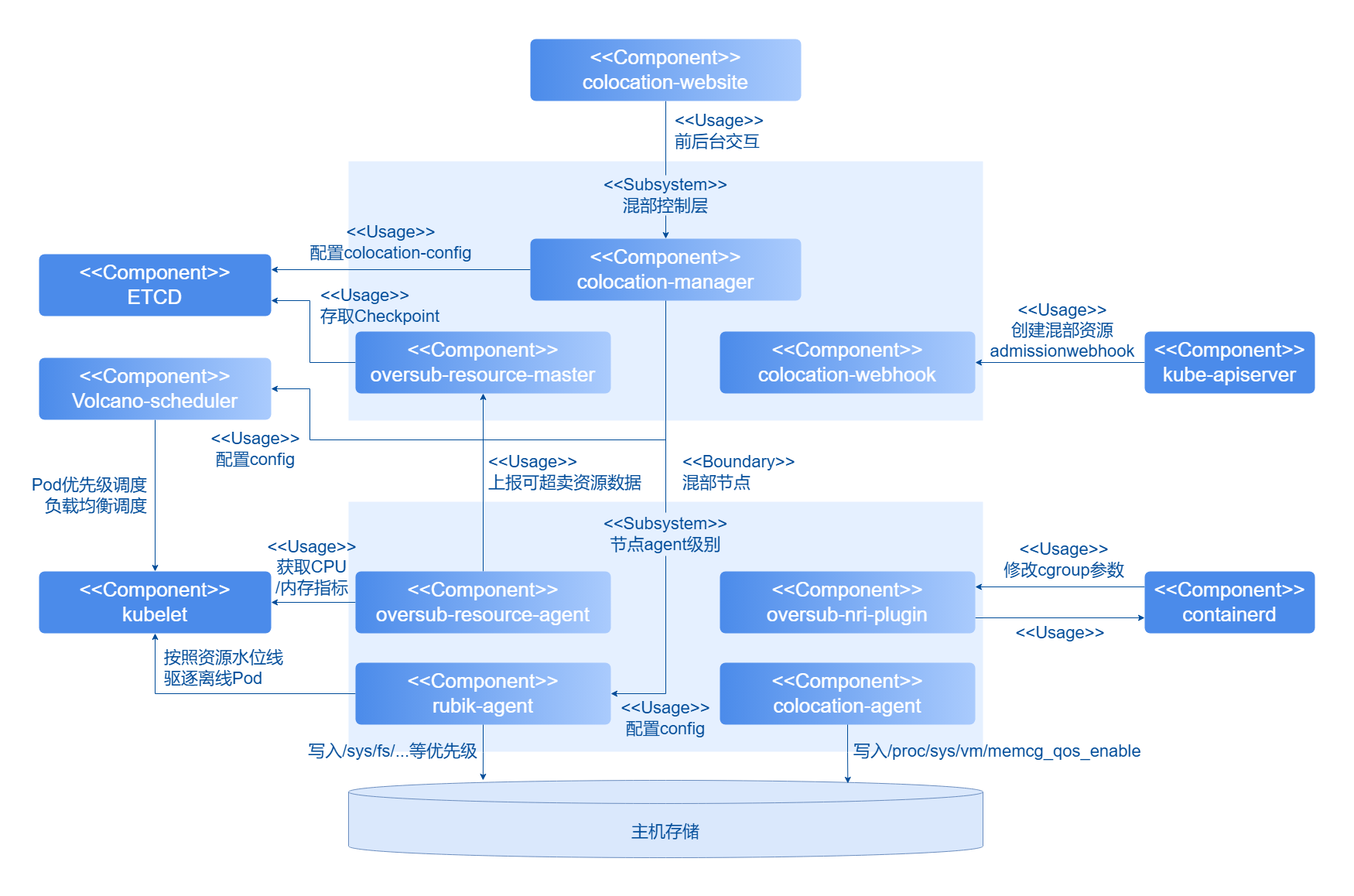
The online-offline colocation component mainly consists of colocation scheduler, colocation unified management component, single-node colocation engine, overselling resource reporting/management component, and NRI plugin. The colocation scheduler currently relies on volcano scheduler for implementation, and the single-node colocation engine is integrated through rubik. The colocation unified management component mainly consists of:
- colocation-website: Deployed as Deployment in the cluster. Online-offline colocation frontend interface design, including colocation statistics visualization, colocation node management, colocation scheduling configuration management, etc.
- colocation-service: Deployed as Deployment in the cluster. Provides service interfaces externally, including colocation monitoring information interfaces, adding/removing colocation node management, colocation scheduling policy configuration.
- colocation-agent: Deployed as Daemonset in the cluster. Mainly responsible for enabling memory QoS management switch on colocation nodes.
Figure 3 Online-Offline Colocation Module Design and Deployment View
The colocation engine and overselling resource management system are provided by the unified colocation-management repository:
- colocation-overquota-agent: Deployed as DaemonSet on cluster overselling nodes. Single-node agent responsible for obtaining node and Pod resource sampling data from kubelet and reporting to the master component. Also integrates rubik colocation engine, providing advanced colocation features such as CPU elastic throttling, asynchronous memory reclaim, memory bandwidth limitation, and PSI interference detection.
- colocation-manager: Deployed as Deployment in the cluster. Contains the overselling master that profiles resource usage patterns of online Pods on each node from sampling data, then combines with system configuration parameters and overselling formulas to update BE allocatable resource amounts on node objects. Also provides admission controller functionality for colocation workloads.
Figure 4 Node Resource Overselling Reporting and Management
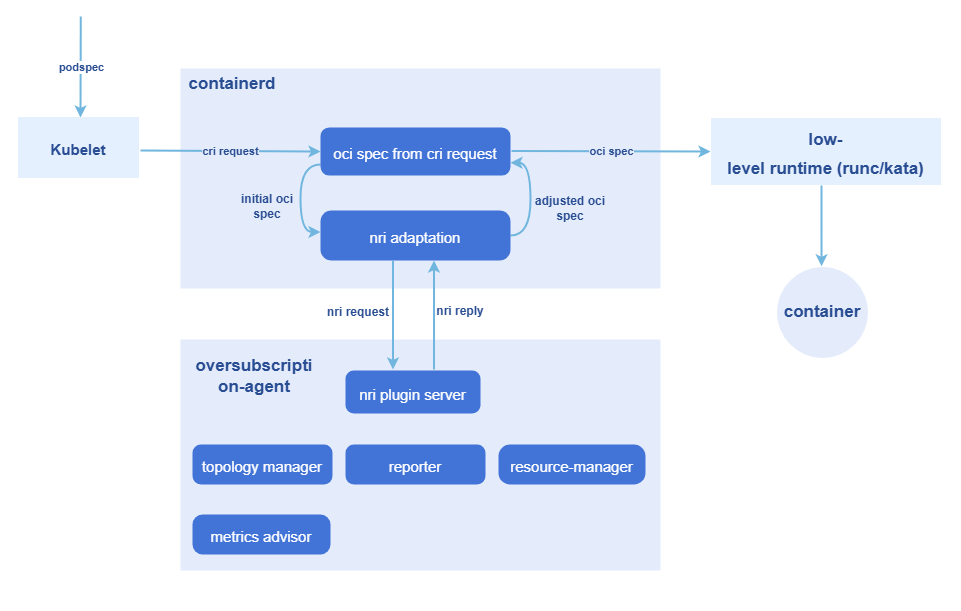
Overselling Pod creation and cgroup management uses NRI mechanism to execute custom logic during multiple lifecycle stages of containers:
- Use NRI mechanism to add custom logic during Pod and container lifecycle hooks.
- Use NRI reply to complete modification of container oci spec.
- Use NRI UpdateContainer to complete modification of actual resources.
The entire process involves two workloads:
- colocation-manager: Deployed as Deployment in the cluster. Admission controller for colocation workloads, responsible for validating workload configuration during colocation workload admission phase to ensure it meets resource setting requirements under the corresponding QoS level, rejecting colocation workloads that do not meet conditions. Also adds necessary resources for colocation scheduling (scheduler, priority, affinity labels, etc.)
- colocation-overquota-agent: Deployed as DaemonSet on overselling nodes. Uses the above NRI mechanism to complete modification of actual resources.
Figure 5 Non-Intrusive Overselling Pod Creation and Cgroup Management Based on NRI Mechanism
Relationship with Related Features
Depends on the resource management module to provide interfaces for delivering workloads, and depends on Prometheus to provide monitoring capabilities.
Related Instances
Code links:
openFuyao/colocation-website (gitcode.com)
openFuyao/colocation-service (gitcode.com)
openFuyao/colocation-management (gitcode.com)
Installation
Prerequisites
Kubernetes v1.21 and above, containerd v1.7.0 and above, and kube-prometheus v1.19 and above have been deployed.
openFuyao's colocation scheduler uses
volcano-schedulerwhich needs to be pre-installed in Kubernetes via helm. Currently, full testing has been performed on version 1.9.0. Functionally, versions later than 1.9.0 are expected to work normally and users can choose to deploy, but functionality correctness is not guaranteed yet.2.1 Install volcano-scheduler via helm
shellhelm repo add volcano-sh https://volcano-sh.github.io/helm-charts helm repo update helm install volcano volcano-sh/volcano --version 1.9.0 -n volcano-system --create-namespace Note:
Note:
If NUMA-aware scheduling component is already installed on openFuyao, the volcano component will be installed by default, so there is no need to pre-install via helm again.2.2 Modify volcano-scheduler default configuration
shellkubectl edit cm -n volcano-system volcano-scheduler-configmapMain modifications as commented below:
yamlapiVersion: v1 data: volcano-scheduler.conf: | actions: "allocate, backfill, preempt" # Ensure actions category and order tiers: - plugins: - name: priority # Ensure priority scheduling is enabled in tiers[0].plugins[0] - name: gang enablePreemptable: false enableJobStarving: false # Ensure enableJobStarving is turned off ... kind: ConfigMap metadata: meta.helm.sh/release-name: volcano meta.helm.sh/release-namespace: volcano-system labels: app.kubernetes.io/managed-by: Helm name: volcano-scheduler-configmap namespace: volcano-systemTip:
When deploying with npu-operator simultaneously, npu-operator may automatically modify volcano-scheduler.conf, overwriting key items (e.g., removing "preempt" from actions, or changing tiers.plugins.gang.enablePreemptable). Please re-check after installing/upgrading npu-operator and restore configuration according to the requirements of this section: ensure actions includes "preempt" and enablePreemptable: false.openFuyao's colocation engine requires the operating system kernel to be at least 4.19 and above. Whether specific colocation features can be enabled can be referred to the Colocation Capability Support module in Colocation Policy Configuration on the interface.
Note:
The complete features of online-offline colocation have been thoroughly verified on openEuler 22.03 LTS-SP3. For other newer versions, you can choose to deploy, but functionality correctness is not guaranteed yet.Enable kubelet core binding and NUMA affinity policy.
Note:
This feature is to enable core binding for HLS-level Pods in conjunction with QoS-level. Only when kubelet's static policy is enabled will HLS-level Pods have exclusivity and NUMA affinity, improving performance of HLS workloads.When using this module, you need to modify the Kubelet Config file. The specific configuration steps are as follows:
4.1 Open the kubelet configuration file.
shellvi /etc/kubernetes/kubelet-config.yamlNote:
If there is no config file at the above location, it can be found at/var/lib/kubelet/config.yaml.4.2 Add or modify configuration items. (When modifying static policy, reserved cpu must be configured simultaneously)
yamlcpuManagerPolicy: static systemReserved: cpu: "0.5" # Note: When the node has few cpu cores, enabling kubeReserved may cause insufficient available cpu on the node, with kubelet crash risk, please enable with caution kubeReserved: cpu: "0.5" topologyManagerPolicy: xxx # best-effort / restricted / single-numa-node4.3 Apply the modification.
rm -rf /var/lib/kubelet/cpu_manager_state systemctl daemon-reload systemctl restart kubelet4.4 Check kubelet running status.
systemctl status kubeletIf kubelet running status is running, it indicates success.
Enable containerd's nri extension feature on colocation nodes.
5.1 On colocation nodes, enter
vi /etc/containerd/config.tomland search for [plugins."io.containerd.nri.v1.nri"].5.2 If it exists, change disable=true to disable=false. If it doesn't exist, add under [plugins]:
[plugins."io.containerd.nri.v1.nri"] disable = false disable_connections = false plugin_config_path="/etc/nri/conf.d" plugin_path="/opt/nri/plugins" plugin_registration_timeout="5s" plugin_request_timeout = "2s" socket_path="/var/run/nri/nri.sock"5.3 After configuration is complete, execute the following command to restart containerd.
shellsudo systemctl restart containerd
Start Installation
In the openFuyao platform, select "Application Market > Application List" in the left navigation bar to enter the "Application List" interface.
Check "Extension Components" on the left type, view all extension components. Or enter "colocation-package" in the search box.
Click the "colocation-package" card to enter the online-offline colocation extension component "Details" interface.
Click "Deploy" to enter the "Deployment" interface.
Enter application name, select installation version and namespace.
Enter the values information to be deployed in "Values.yaml" under parameter configuration.
Click "Deploy" to complete deployment.
Click "Extension Component Management" in the left navigation bar to manage this component.
Note:
After deployment, colocation support configuration needs to be performed on nodes in the cluster. This operation may cause workloads on that node to be evicted and rescheduled. In production environments, please plan colocation nodes in the cluster reasonably and use with caution.
Independent Deployment
Compared to application market installation and deployment, this component provides independent deployment functionality with the following steps:
For independent deployment, Kubernetes v1.26 and above, prometheus, containerd, and volcano v1.9.0 still need to be deployed in advance.
Pull the image.
shellhelm pull oci://cr.openfuyao.cn/charts/colocation-package --version xxxReplace xxx with the helm image version to pull, for example: 0.13.0
Extract the installation package.
shelltar -zxvf colocation-package-xxx.tgzDisable openFuyao and Oauth switches.
shellvi colocation-package/values.yamlChange the
colocation-website.enableOAuthandcolocation-website.openFuyaooptions to false.Set service to NodePort type.
shellvi colocation-package/values.yamlModify
colocation-website.service.typetoNodePortConnect to prometheus.
shellvi colocation-package/values.yamlFor independent deployment, the monitoring component needs to be installed in the cluster. Modify the
colocation-service.serverHost.prometheusfield to the metric query address and port exposed by prometheus in the current cluster, for example:http://prometheus-k8s.monitoring.svc.cluster.local:9090.Independent installation.
helm install colocation-package ./Access the independent frontend.
You can access the independent frontend by entering "http://management plane client login IP address:30880" in a browser.
View Overview
In the left navigation bar of the openFuyao platform, select "Computing Optimization Center", then "Online-Offline Colocation > Overview" to enter the "Overview" interface of online-offline colocation, which displays the workflow of online-offline colocation.
Prerequisites
The "colocation-package" extension component has been deployed in the application market.
Background Information
View the workflow of online-offline colocation, including environment preparation, colocation policy configuration, workload deployment, and online-offline colocation monitoring.
Usage Restrictions
None.
Operation Steps
Click "Online-Offline Colocation > Overview" to enter the "Overview" interface.
- "Environment Preparation" includes modifying kubelet and containerd configurations required to enable node online-offline colocation functionality. Click
 to display configuration methods.
to display configuration methods. - "Colocation Policy Configuration" can click "Configure Colocation Policy" after the description to jump to the colocation policy configuration interface.
- "Workload Deployment" is the actual use of scheduling functionality for workload scheduling. Clicking "Deploy Workload" can jump to the workload deployment interface.
- "Online-Offline Colocation Monitoring" displays health monitoring information for cluster-level and node-level colocation. Clicking "View Online-Offline Colocation Monitoring" can jump to the colocation monitoring interface.
Using Colocation Policy Configuration
In the left navigation bar of the openFuyao platform interface, select "Computing Optimization Center", then "Online-Offline Colocation > Colocation Policy Configuration" to enter the "Colocation Policy Configuration" interface. This interface displays colocation-related node list information in the cluster, provides a colocation parameter configuration window, and supports enabling or disabling colocation labels for nodes in the node list, helping achieve balanced distribution and stable operation of cluster resources.
Enabling or Disabling Node Colocation Labels
Background Information
Users need to change the colocation label status of specified nodes.
Usage Restrictions
Changing node colocation labels may cause Pods on that node to be evicted. Please plan colocation capabilities of nodes in the cluster reasonably.
Operation Steps
Click the switch in the "Enable Colocation Node" column corresponding to the node in the colocation node list to enable or disable the node colocation capability status.
The interface displays "Node xxx has enabled colocation functionality" or "Node xxx has disabled colocation functionality" to indicate successful switching.
Using Colocation Policy Parameter Configuration
Background Information
This interface provides parameter configuration functionality for load-aware scheduling, offline workload watermark eviction, and advanced colocation features. You can set actual load thresholds for CPU and memory to control scheduling policies for new workloads and avoid node overload. After configuring offline workload watermark eviction, when node resource usage exceeds the set watermark, offline job eviction is automatically triggered to release resources.
Advanced colocation features include:
- CPU Elastic Throttling: When node load is low, allows LS-level Pods to dynamically break through CPU limits, automatically converging when load increases.
- Asynchronous Memory Reclaim: Hierarchical memory reclaim based on different QoS levels, prioritizing reclaim of BE-level Pod memory.
- Memory Bandwidth Limitation: Uses hardware technology to limit BE-level Pod occupation of memory bandwidth and CPU cache.
- PSI Interference Detection: Automatically detects and evicts offline Pods that interfere with online workloads based on system pressure metrics.
Usage Restrictions
- Load-aware scheduling threshold range is 0-100%, default is 60% to balance resource utilization and stability.
- Running workloads are not affected by threshold adjustments.
- Offline workload watermark eviction threshold range is 0-99%, only affects offline jobs, critical online workloads are not affected. Eviction process may cause brief service fluctuations.
- Advanced colocation feature restrictions:
- CPU elastic throttling and asynchronous memory reclaim require cgroup v2 support, recommended to use openEuler 22.03 LTS SP3 and above.
- Memory bandwidth limitation requires hardware support (Intel RDT or ARM MPAM), only takes effect in physical machine environments.
- Some features require specific kernel interfaces, the system will automatically detect node support status.
Operation Steps
In the "Colocation Policy Configuration" interface, click "Colocation Policy Parameter Configuration" in the upper right corner of the colocation node list.
In the popup, click the corresponding switches for "Load-Aware Scheduling" and "Offline Workload Watermark Eviction" or other advanced colocation features.
Note:- After "Load-Aware Scheduling" and "Offline Workload Watermark Eviction" are enabled, node CPU and memory thresholds default to 60%, and can be modified according to prompts.
- Advanced colocation feature defaults:
- CPU Elastic Throttling: Load high watermark defaults to 60%, alarm watermark defaults to 80%.
- Memory Bandwidth Limitation: L3 cache allocation (low/mid/high priority) defaults to 20%/30%/50%, memory bandwidth allocation defaults to 20%/30%/50%. By default, all offline Pods use dynamic control group. To customize control group level, you can specify by adding
volcano.sh/cache-limit: "low/mid/high"annotation to Pods. - PSI Interference Detection: Monitored resources default to CPU and memory, 10-second average pressure threshold defaults to 5.0%.
- Asynchronous Memory Reclaim: No additional parameter configuration required, takes effect automatically when enabled.
After modifying corresponding configuration parameters and thresholds, click "OK" to save changes.
Note:- Advanced colocation feature switch status will automatically determine availability based on node hardware and kernel support.
- For unsupported features, the switch will be grayed out and display specific reasons for non-support.
- Configuration modifications take effect automatically within about 30 seconds, no need to restart related components.
- Regarding memory bandwidth limitation feature: The system defaults to dynamic control group managing all offline Pods, the set low/mid/high watermark parameters only take effect when users manually specify Pod control groups.
Using Colocation Monitoring
In the left navigation bar of the openFuyao platform, select "Computing Optimization Center", then "Online-Offline Colocation > Colocation Monitoring" to enter the "Cluster-Level Colocation Monitoring" interface by default, which displays colocation-related data monitoring panels in the cluster.
Cluster-Level Colocation Monitoring
This interface provides monitoring of colocation-related data in the colocation cluster, including colocation node information, colocation workload information, and resource usage in the cluster.
Hover the mouse over the curve chart of the corresponding monitoring metric to display specific data information.
In the "Legend" section of each chart, you can click individual legend items to select whether to display that data in the chart, facilitating comparison of different data.
Node-Level Colocation Monitoring
Click the "Node-Level Colocation Monitoring" tab to switch to the node-level monitoring interface, where you can view node colocation data information, such as total physical resources used by each node and resource usage by HLS, LS, BE and other types of Pods.
Hover the mouse over the curve chart of the corresponding monitoring metric to display specific data information.
In the "Legend" section of each chart, you can click individual legend items to select whether to display that data in the chart, facilitating comparison of different data.
In the filter box in the upper right corner of the interface, you can select or deselect the display of some nodes.
Enabling NUMA Affinity Enhancement
Prerequisites
The node needs to have multi-NUMA architecture, and NUMA affinity functionality has been enabled in the configuration (configMap).
Background Information
On multi-NUMA node servers, cross-NUMA node memory access brings higher latency, affecting the performance of latency-sensitive (LS-level) workloads. By enabling NUMA affinity enhancement, containers in LS-level Pods are bound to the same NUMA node, reducing memory access latency and improving workload stability.
Usage Restrictions
Only supports LS-level (low-priority online workloads) Pods, other QoS levels (such as HLS, BE) are not affected.
After enabling this feature, resource allocation is only intercepted before Pod startup, not affecting the scheduling phase before enabling.
Operation Steps
Colocation overselling functionality has been enabled.
Confirm that nodes have enabled colocation. For specific operations, refer to the related operation steps in Enabling or Disabling Node Colocation Labels.
Enable NUMA affinity functionality
Edit ConfigMap to enable NUMA functionality:
bashkubectl edit configmap colocation-config -n openfuyao-colocationChange
enablefromfalsetotrueinnuma-affinity-optionsin the configuration.Wait 30 seconds for the component to monitor the configuration change and automatically take effect.
Deploy application.
Add LS-level annotation to Pods that need NUMA affinity.
yamlannotations: openfuyao.com/qos-level: "LS"Verify the result.
After the feature is enabled and the application is deployed, the system will automatically perform the following operations:
- Detect Pod QoS level.
- Select the best NUMA node for LS-level Pods.
- Limit Pod CPU usage to the selected NUMA node.
You can verify the feature is working properly by checking component logs:
kubectl logs -n openfuyao-colocation -l app.kubernetes.io/name=colocation-overquota-agentSeeing the log "Successfully applied NUMA affinity for LS pod" indicates the feature is working properly.
- If a single NUMA node has insufficient resources, the system will automatically select other suitable nodes.
- HLS and BE level Pods are not affected by NUMA affinity and are handled according to original policies.
Licensed under the MulanPSL2
 YueGongWangAnBei No.44030002007300
YueGongWangAnBei No.44030002007300