AI推理集成部署
特性介绍
AI推理集成部署(InferNex)是一个专为云原生环境下AI推理服务优化所设计的端到端集成部署方案。该方案基于Kubernetes Gateway API Inference Extension (GIE) 和主流LLM技术栈构建,通过Helm Chart将开源网关、智能路由、高性能推理后端、全局KVCache管理、扩缩容决策框架及推理可观测体系等核心加速模块无缝集成。它提供从请求接入、动态路由、推理执行到资源管理与监控的完整加速链路,旨在提升推理吞吐量并降低TTFT/TPOT时延,实现一站式的高效AI服务部署体验。
应用场景
- 聚合推理场景:支持聚合推理架构,适用于中小规模推理场景。
- PD分离推理场景:支持Prefill-Decode分离推理架构,适用于大规模、高吞吐推理场景。
- AI推理软件套件场景:支持原AI推理软件套件模式,适用于一体机场景下的软件部署。具体特性使用方法请参考指南。
能力范围
- 支持用户根据场景需求选装开源网关、智能路由、全局KVCache管理、推理可观测组件。
- 智能路由支持与多种开源网关集成,开源网关需适配GIE。
- 智能路由提供KVCache感知、分桶调度等高级路由策略,支持多种场景下优化推理请求调度。
- 智能路由提供容灾能力,包含自动切流、故障感知以及请求重试。
- 支持以聚合/PD分离两种模式部署推理引擎,并且可以配置推理引擎节点数量。
- 支持配置Mooncake作为分布式KVCache管理后端。
- 支持在内置的vLLM启动命令及常规配置项(模型长度、批处理大小、内存利用率、块大小等)基础上追加额外启动参数。
- 支持配置不同版本vLLM推理引擎。
- 支持推理引擎节点级别的精细化资源配置,包括CPU限制、内存限制、环境变量、存储卷挂载等。
- 适配华为昇腾910B4芯片的推理加速。
- 支持用户配置推理芯片。
- 实现从AI网关、推理引擎、Mooncake到基础设施的全链路指标采集。
- AI网关:性能、资源消耗、安全与合规审计等。
- 推理引擎:API Server、模型输入输出、推理过程等。
- Mooncake:Mooncake master、Mooncake client和transfer engine。
- 基础设施:Ray、K8s和硬件。
- 提供独立的硬件健康诊断模块,周期性采集NPU/GPU温度、功耗、错误码等底层指标,并通过分布式消息队列系统实时上报。诊断模块订阅并分析采集数据,结合设备型号、驱动与固件信息,基于阈值规则与异常指标分析,识别典型故障模式并输出诊断结论与处置建议,实现从数据采集到健康评估的闭环。
- 提供SLA相关指标(如吞吐率、延迟等),用于支撑推理服务的自动扩缩容决策,实现基于负载与性能的弹性伸缩。
- 提供潮汐算法,支持在指定时间段拉起/删除业务资源。
- 提供扩缩容决策框架,支持指标驱动与事件驱动来控制资源副本的扩缩容,并且支持用户自定义扩缩容决策算法及自定义资源管理逻辑的灵活扩展。
- 提供动态PD组扩缩容能力,利用抽象资源管理对象纳管PD实例,实现可按比例的动态PD扩缩容。
- 支持以Helm形式在K8s环境一键部署推理集群。
亮点特征
- 组件选装与解耦:开源网关、智能路由、全局KVCache管理、推理可观测组件均采用选装式设计,用户可根据实际场景按需启用或关闭,并支持替换为自研或第三方具备等价能力的组件。
- 开源网关能力集成: 支持与适配GIE的开源网关(Istio、Envoy AI Gateway等)集成,具备服务发现、故障感知、请求重试、流量控制、安全认证等关键网关能力。
- KVCache Aware路由策略:相比传统负载均衡,通过感知全局推理节点的KVCache状态实现更智能的请求路由,减少重复KVCache计算。
- PD-Bucket路由策略:PD分离架构下的分桶调度策略,在长短请求、中高并发场景提升推理吞吐量。
- Prefill-Decode分离架构:支持业界先进的PD分离架构,大幅提升LLM推理吞吐量。
- vLLM Mooncake集成:vLLM v1架构集成Mooncake分布式KVCache管理系统,提供分布式KVCache池化存储与跨实例的KVCache高速传输,提升缓存复用效率。
- 秒级指标推送:集成NATS分布式消息队列系统,实现高效的秒级指标推送。采集模块在获取硬件健康数据后,立即通过NATS将数据推送至诊断模块。该机制确保诊断模块能够快速接收到最新状态信息,进行及时的异常检测和故障分析。
- PD-Orchestrator特性:集成潮汐算法、扩缩容决策框架与动态PD扩缩容三大能力,覆盖PD实例独立扩缩容、PD实例整组按比例扩缩容、指标驱动扩缩容、潮汐业务定时触发扩缩容等多个场景,保证业务在流量激增时的服务可用性。
- 一键部署:通过Helm Chart实现三大组件在K8s环境一键式集成部署。
实现原理
图1 AI推理集成组件图
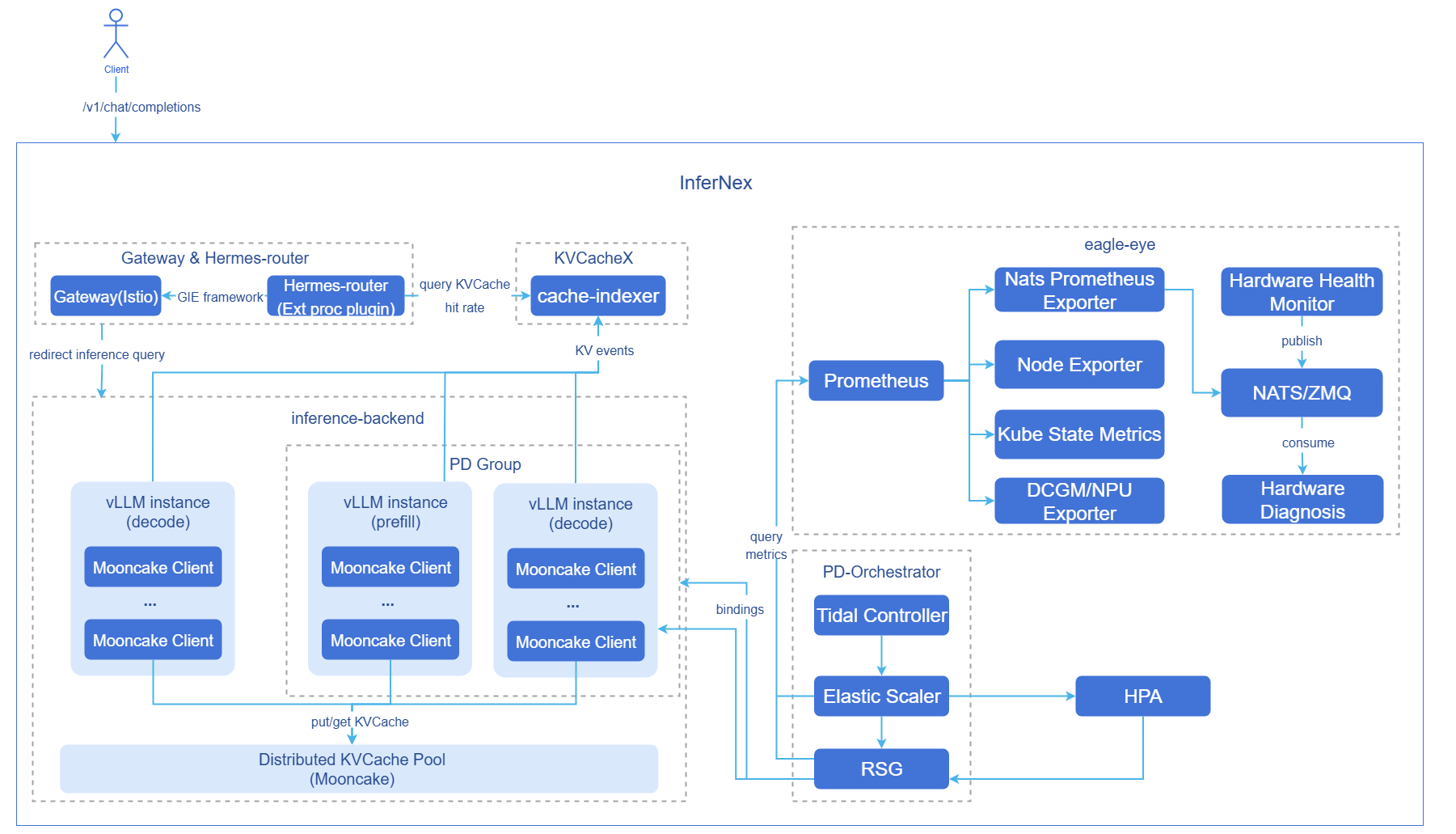
- Hermes-router:智能路由模块。负责接收用户请求并根据路由策略转发到最优的推理后端服务。实现原理参见《AI推理赫尔墨斯路由》。
- cache-indexer:KVCache全局管理器,为路由决策提供数据支持。
- inference-backend:推理后端模块,基于vLLM提供高性能大模型推理服务,由1个Proxy Server实例,n个vLLM Prefill推理引擎实例和n个vLLM Decode推理引擎实例组成。
- vLLM:vLLM推理引擎实例。
- Mooncake:分布式KVCache池化存储与提供PD实例之间的KVCache P2P高速传输。
- eagle-eye:提供近实时可观测指标发布订阅机制,保障关键指标毫秒级时延;覆盖推理场景的业务运行态、系统运行态和硬件健康指标,并提供硬件故障感知与诊断模块。实现原理参见《AI推理鹰眼》。
- PD-Orchestrator:由Tidal Controller、Elastic Scaler和RSG三个组件组成,提供潮汐定时扩缩、指标驱动扩缩与多资源按比例扩缩能力。实现原理参见《AI推理弹性伸缩》、《AI推理潮汐算法》、《资源组扩缩容》。
组件初始化流程:
开源网关(默认istio):
- 用户部署Istiod控制平面后,Istiod启动并开始侦听Kubernetes Gateway API相关CRD(GatewayClass、Gateway、HTTPRoute等)。
- Istio自动创建GatewayClass资源,声明自身为网关控制器。
- 用户配置Gateway CR后,Istiod生成对应的Envoy配置,在目标命名空间中自动创建Envoy Proxy的Deployment和Service,作为实际网关入口。
- 数据平面完成配置加载,网关开始正常转发外部流量。
智能路由:
- 智能路由读取配置。
- 启动推理后端服务发现模块(周期性更新后端列表)。
- 启动推理后端指标收集模块(周期性更新后端负载指标)。
推理后端:
- 根据配置启动vLLM推理引擎实例。
- vLLM推理引擎实例绑定硬件设备,加载模型。
- 每个vLLM推理引擎实例启动Mooncake客户端,注册内存/SSD存储池。
- Prefill推理引擎实例与Decode推理引擎实例与对方所暴露的KV connector端口建立连接。
- PD分离部署模式下,Proxy Server组件启动,开始对推理引擎实例自动发现(周期性更新推理引擎实例列表)。
全局KVCache管理器:
- 根据配置启动cache-indexer实例。
- 启动推理引擎实例自动发现模块(周期性更新推理实例列表)。
PD-Orchestrator:
- 根据配置启动tidal-scheduler控制器、elastic-scaler控制器、ResourceScalingGroup控制器。
- 根据配置部署默认ElasticScaler CR实例与ResourceScalingGroup CR实例,绑定vLLM推理后端。
- 创建HPA资源,根据CPU利用率等指标对vLLM推理后端进行PD整组扩缩。
请求流程:
- 请求接入:用户请求首先到达GIE开源网关Istio。
- KVCache查询:网关插件Hermes-router向cache-indexer查询该请求在集群中的前缀命中信息。
- 路由决策:Hermes-router基于KVCache命中情况、GPU利用率等指标选择最优推理后端服务。
- 请求转发:开源网关将请求转发到选定的推理后端服务。
- KVCache获取:Prefill节点推理引擎尝试从Mooncake KVCache池获取已缓存的前缀KVCache。
- 预填充计算:Prefill节点推理引擎执行未命中KVCache部分的token预填充计算,并将新生成的KVCache写入Mooncake KVCache池。
- KVCache传输:Prefill节点推理引擎通过Mooncake将请求的KVCache高速传输给Decode节点推理引擎。
- 推理生成:Prefill推理引擎生成首token结果,Decode推理引擎基于接收到的KVCache持续生成后续token。
- 推理实例动态扩缩容:推理后端服务压力增大/减小时,HPA监控相应指标并计算需要扩容/缩容的副本数,实现推理后端服务扩容/缩容。
- 结果返回:推理引擎生成的推理结果返回开源网关,随后返回客户端。
- 全局KVCache管理异步更新:Prefill推理引擎在预填充过程中产生KV Event,cache-indexer订阅该KV Event并实时更新全局KVCache元数据。
与相关特性的关系
- 智能路由Hermes-router组件依赖推理引擎(如vLLM)提供推理服务及指标接口。
- KVCache全局管理器cache-indexer组件依赖推理引擎(如vLLM)提供KVCache存储、移除事件。
- 潮汐算法Tidal-scheduler需要依赖弹性扩缩框架elastic-scaler对需要定时扩缩的资源对象的副本数进行修改。
相关实例
示例参考:values.yaml
安装
前提条件
硬件要求
- 每个推理节点至少一张推理芯片。
- 每个推理节点至少32GB内存,4CPU核。
软件要求
- Kubernetes v1.33.0及以上版本。
- 已安装npu-operator组件。
- InferNex会一键部署开源网关,默认使用Istio,需要确保环境没有冲突。
- InferNex包含的组件在目标命名空间尚未安装部署hermes-router、Inference Backend、cache-indexer。
- InferNex包含的组件在eagle-eye、nats命名空间尚未安装部署eagle-eye。
网络要求
- 在线安装能够访问镜像仓库:oci://cr.openfuyao.cn。
权限要求
- 用户具备创建RBAC资源的权限。
开始安装
独立部署
本特性有以下两种途径独立部署:
从openFuyao官方镜像仓库获取项目安装包
拉取项目安装包。
bashhelm pull oci://cr.openfuyao.cn/charts/infernex --version xxx其中
xxx需替换为具体项目安装包版本,如0.21.1。拉取得到的安装包为压缩包形式。解压安装包。
bashtar -xzvf infernex-xxx.tgz其中
xxx需替换为具体项目安装包版本,如0.21.1。安装部署。
以命名空间
ai-inference、release名称infernex为例,在infernex同级目录下执行如下命令:bashhelm install -n ai-inference infernex ./infernex
从openFuyao GitCode仓库获取完整项目
从仓库拉取项目。
bashgit clone https://gitcode.com/openFuyao/InferNex.git安装部署。
以命名空间
ai-inference、release名称infernex为例,在InferNex同级目录下执行如下命令:bashcd InferNex/charts/infernex helm dependency build helm install -n ai-inference infernex .
离线安装
从openFuyao制品仓库获取离线安装包。
bashwget https://openfuyao.obs.cn-north-4.myhuaweicloud.com/openFuyao/ext-components/InferNex/openFuyao-infernex-offline-v26.03.tar.gz 说明:
说明:
若用户想手动制作InferNex离线包,可以参考离线包制作指南。解压离线安装包。
bashtar -xzvf openFuyao-infernex-offline-v26.03.tar.gz解压helm chart安装包、解压镜像到本地仓库、解压InferNex内置模型缓存文件。
bashcd openFuyao-infernex-offline-v26.03 && bash install.sh安装部署。
若用户想使用自定义模型文件,请参考自定义模型目录配置。
以命名空间
ai-inference、release名称infernex为例,在chart包文件infernex的同级目录下执行如下命令:bashhelm install -n ai-inference infernex ./infernex
配置AI推理集成部署
前提条件
- 已获取InferNex项目文件。
操作步骤
准备
values.yaml配置文件。参考开始安装章节找到
values.yaml配置文件。配置全局配置。
global.image.pullPolicy:控制InferNex部署所有镜像的拉取策略,在线部署时默认为
IfNotPresent,离线部署时默认为Never。global.imagePullSecrets:私有镜像仓库的Secret配置,用于从私有镜像仓库拉取镜像。例如:
[{"name": "registry-secret"}]。global.env:定义所有
inference-backend服务实例的默认环境变量,这些环境变量会被注入到所有推理引擎容器和cache-indexer容器中。常见配置HuggingFace离线下载开关、Huggingface访问的K8s Secret。global.autoDownloadModel:是否通过InferNex自动下载Huggingface模型。若想使用本地非Huggingface模型或处于离线环境,需设置为
false。global.modelName:推理模型名称(必填)。若未配置
global.modelPath,vLLM会通过Huggingface模型名称方式加载权重。若已配置global.modelPath,vLLM会将该配置作为模型别名,用于推理请求的model字段匹配。默认使用的推理模型为"Qwen/Qwen3-8B"。global.modelPath:推理模型权重本地路径(可选)。若配置,则vLLM使用本地路径方式启动,否则使用
global.modelName配置的模型名称加载Huggingface模型。当前版本该配置项不可与cache-indexer组件共用。因模型权重通过global.cachePath方式挂载到容器的/root/.cache目录,所以该配置应为/root/.cache/{cachePath后的模型目录}。global.cachePath:宿主机上存储
HuggingFace模型缓存的路径,结构为{缓存目录}/huggingface/hub/{模型目录},该路径会通过hostPath方式挂载到所有推理引擎容器和cache-indexer容器的/root/.cache目录。关于自定义模型目录配置的详细说明和示例,请参考自定义模型目录配置。默认配置的宿主机模型缓存路径为/home/llm_cache。本地非Huggingface模型配置示例:宿主机本地模型路径
/mnt/public/models/my_models/Qwen3-8B-W8A8/,则InferNex配置为:yamlglobal: env: - name: HF_HUB_OFFLINE value: "0" autoDownloadModel: false modelName: "Qwen3-8B-W8A8" modelPath: "/root/.cache/Qwen3-8B-W8A8/" cachePath: "/mnt/public/models/my_models/"
配置智能路由参数。
配置网关参数
- inferenceGateway.enabled:开源网关开关。
true开启,false关闭。 - inferenceGateway.name:Gateway资源的名称。必须与
hermes-router.httpRoute.parentRef.name保持一致。 - inferenceGateway.className:Gateway类名称。缺省值
"istio",表示使用Istio控制平面管理。 - inferenceGateway.listeners:定义侦听器配置。
name: http:侦听器名称。port: 80:侦听端口。protocol: HTTP:协议类型。
配置路由镜像拉取
- hermes-router.enabled:智能路由开关。
true开启,false关闭。注意,由于智能路由本身是扩展插件,无法在无网关的情况下单独使用。 - hermes-router.image.repository:智能路由镜像地址。
- hermes-router.image.tag:智能路由镜像版本。
配置路由策略
hermes-router.inferenceExtension.replicas:智能路由副本数量。默认为
1。hermes-router.inferenceExtension.pluginsConfigFile: 指定要使用的路由策略配置文件名称,该名称必须与
hermes-router.inferenceExtension.pluginsCustomConfig中的键名一致。hermes-router.inferenceExtension.pluginsCustomConfig: 定义自定义的路由策略配置内容。目前支持以下路由策略:
- KVCache Aware(聚合):参考
epp-aggregate-kv-cache-aware.yaml。 - KVCache Aware(PD分离):参考
epp-pd-kv-cache-aware.yaml。 - PD分离分桶调度:参考
epp-pd-bucket.yaml。 - PD分离随机调度:参考
epp-random-pd.yaml。
配置时必须包含路由策略中的插件配置和调度配置,具体配置示例可参考:hermes-router路由策略参考配置,该链接提供了上述所有路由策略的完整参考配置。
- KVCache Aware(聚合):参考
配置InferencePool
- hermes-router.inferencePool.modelServers.matchLabels: 推理服务标签选择器,用于选择加入InferencePool的Pod,Pod必须同时满足所有标签,且仅在同一命名空间内匹配,不支持跨命名空间。
- hermes-router.inferencePool.targetPorts: InferencePool里各个推理服务实际侦听的端口号,用于处理推理流量。默认推理端口为
8000。 - hermes-router.inferencePool.modelServerType:推理引擎类型。默认为
vllm。
配置HTTPRoute
- hermes-router.httpRoute.inferenceGatewayName:Gateway资源的名称。必须与
inferenceGateway.name保持一致。
配置请求重试
- hermes-router.provider.retryConfig:定义请求重试配置。
enabled:请求重试开关。true开启,false关闭。默认false。retryOn:触发重试的错误类型列表,典型可选值包括:connect-failure、refused-stream、unavailable、cancelled、retriable-status-codes、5xx、reset等,可按需组合。默认全选。numRetries:单次请求允许的最大重试次数。默认次数为3。
- hermes-router.provider.istio.destinationRule.tls:定义Istio网关与推理后端的通信规则。
mode:Istio与后端通信时的TLS模式,可选:DISABLE(不启用TLS)、SIMPLE(单向TLS)、MUTUAL/ISTIO_MUTUAL(双向 TLS,依赖证书或Istio提供的身份)。默认SIMPLE。insecureSkipVerify:是否跳过对后端服务证书的校验,可选:true(跳过)、false(不跳过)。默认true。
- inferenceGateway.enabled:开源网关开关。
配置推理后端参数。
配置推理后端镜像参数
- inference-backend.images.inferenceEngine:配置推理引擎镜像(repository、tag)。InferNex默认配置使用
vllm-ascend:v0.13.0推理引擎。 - inference-backend.images.proxyServer:配置Proxy Server镜像(repository、tag)。
配置推理后端环境变量
- inference-backend.env:推理后端环境变量总配置,这些环境变量会被注入到所有推理服务的推理引擎容器(Prefill、Decode)和Proxy Server容器中。用户可根据实际需求参考vllm-ascend环境变量配置说明文档自行配置。
配置推理后端文件挂载参数
- inference-backend.volumeMounts:所有vLLM deployment都会挂载的volumeMounts配置。默认配置包含昇腾设备相关的volumeMounts。用户可以根据需要增添更详细的挂载项,详细配置说明请参考推理后端默认挂载配置。
- inference-backend.volumes:所有vLLM deployment都会挂载的volumeMounts配置。默认配置包含昇腾设备相关的volumes。详细配置说明请参考推理后端默认挂载配置。
配置推理服务
inference-backend.services:推理服务配置,支持用户配置多个独立的vLLM推理服务。每个服务可独立配置模型、部署模式(聚合模式或PD分离模式)、资源等参数,实现多种部署形态推理服务的混合部署。
基础配置
- name:推理服务名称。
- enabled:是否部署该服务。InferNex要求推理后端至少要有一个推理服务是开启状态。
- mode:推理后端服务模式,共有
aggregated和pd两种可选,分别表示聚合架构和PD分离架构。 - service.port:Service服务端口,默认配置为
8000。 - pdGroupID:PD模式分组ID,在PD分离架构下需要设置,表示该推理服务下的所有Proxy Server服务,Prefill和Decode推理后端服务均在该分组内,用于智能路由策略发现和过滤服务。
配置推理引擎Connector
kvTransferConfig.connectorConfig:配置KVCache Connector,用于定义Prefill和Decode阶段KVCache复用方式。提供YAML格式的配置对象,配置会按照键值对自动转换为JSON格式,并且
kv_role、kv_rank、engine_id、tp_size、dp_size等prefill/decode节点特定字段会自动填充,无需手动配置(用户手动配置可以覆盖自动填充)。PD分离模式部署kv_connector推荐使用MultiConnector(结合MooncakeConnectorV1和AscendStoreConnector),聚合模式部署推荐使用AscendStoreConnector。因vllm/vllm-ascend版本不同,connector的名称、细节配置项存在不同,详细配置说明请参考目标vllm/vllm-ascend版本文档。InferNex默认配置使用
vllm-ascend:v0.13.0推理引擎,用户可以参考vllm-ascend v0.13.0版本文档。kvTransferConfig.mooncake.configPath:使用Mooncake作为推理引擎的KVCache管理系统时,推理引擎内Mooncake客户端启动的配置项文件。默认路径为
"/app/mooncake.json"。kvTransferConfig.mooncake.use_store:使用Mooncake作为推理引擎的KVCache管理系统时,用于控制是否使用Mooncake Store模式。若上方connector类型应用了Mooncake Store类型Connector,需要将此配置开启。
kvTransferConfig.mooncake.config:Mooncake客户端配置文件内容(yaml格式)。推理引擎pod的initContainer会自动转换并生成
mooncake.json配置文件让推理引擎内的Mooncake客户端直接使用。详细配置项说明请参考Mooncake文档。
配置PD分离模式下推理引擎启动项
- pd.prefill.replicas:Prefill引擎副本数。
- pd.prefill.tensorParallelSize:Prefill引擎张量并行度。
- pd.prefill.pipelineParallelSize:Prefill引擎流水线并行度,当前仅支持配置为1。
- pd.prefill.dataParallelSize:Prefill引擎数据并行度。
- pd.prefill.cardCount:用于指定分配给Prefill引擎的推理卡数量;未配置时默认取
tp*dp*pp。在多机部署单模型场景下,必须手动设置该参数,否则基于tp*dp*pp的默认计算会产生偏差。 - pd.prefill.enablePrefixCaching:Prefill引擎是否启用前缀缓存。
- pd.prefill.maxModelLen:Prefill引擎最大模型长度。
- pd.prefill.maxNumBatchedTokens:Prefill引擎最大批处理token数。
- pd.prefill.gpuMemoryUtilization:Prefill引擎显存利用率。
- pd.prefill.blockSize:Prefill引擎块大小。
- pd.prefill.env:Prefill引擎容器环境变量列表,用于配置该推理服务Prefill推理引擎Pod特殊需要的环境变量。
- pd.prefill.volumeMounts:Prefill引擎容器volumeMounts列表,用于配置该推理服务Prefill推理引擎Pod特殊需要的volume挂载。
- pd.prefill.volumes:Prefill引擎容器volumes列表,用于配置该推理服务Prefill推理引擎Pod特殊需要的volumes。
- pd.prefill.extraArgs:Prefill引擎额外启动参数列表。用户在部分场景下需要性能调优的启动命令专项配置,此项配置负责将额外配置项追加到推理引擎启动命令中。
- pd.decode.replicas:Decode引擎副本数。
- pd.decode.tensorParallelSize:Decode引擎张量并行度。
- pd.decode.pipelineParallelSize:Decode引擎流水线并行度,当前仅支持配置为1。
- pd.decode.dataParallelSize:Decode引擎数据并行度。
- pd.decode.cardCount:用于指定分配给Decode引擎的推理卡数量;未配置时默认取
tp*dp*pp。在多机部署单模型场景下,必须手动设置该参数,否则基于tp*dp*pp的默认计算会产生偏差。 - pd.decode.enablePrefixCaching:Decode引擎是否启用前缀缓存。
- pd.decode.maxModelLen:Decode引擎最大模型长度。
- pd.decode.maxNumBatchedTokens:Decode引擎最大批处理token数。
- pd.decode.gpuMemoryUtilization:Decode引擎显存利用率。
- pd.decode.env:Decode引擎容器环境变量列表,用于配置该推理服务Decode推理引擎Pod特殊需要的环境变量。
- pd.decode.volumeMounts:Decode引擎容器volumeMounts列表,用于配置该推理服务Decode推理引擎Pod特殊需要的volume挂载。
- pd.decode.volumes:Decode引擎容器volumes列表,用于配置该推理服务Decode推理引擎Pod特殊需要的volumes。
- pd.decode.extraArgs:Decode引擎额外启动参数列表。
- pd.proxyServer.discoveryInterval:Proxy Server对推理后端服务发现间隔(单位:秒)。
配置聚合模式下推理引擎
- aggregated.replicas:聚合模式推理引擎副本数。
- aggregated.enablePrefixCaching:聚合模式推理引擎是否启用前缀缓存。
- aggregated.tensorParallelSize:聚合模式推理引擎张量并行度。
- aggregated.pipelineParallelSize:聚合模式推理引擎流水线并行度。
- aggregated.dataParallelSize:聚合模式推理引擎数据并行度。
- aggregated.cardCount:用于指定分配给聚合模式推理引擎的推理卡数量;未配置时默认取
tp*dp*pp。在多机部署单模型场景下,必须手动设置该参数,否则基于tp*dp*pp的默认计算会产生偏差。 - aggregated.gpuMemoryUtilization:聚合模式推理引擎显存利用率。
- aggregated.blockSize:聚合模式推理引擎块大小。
- aggregated.maxModelLen:聚合模式推理引擎最大模型长度。
- aggregated.maxNumBatchedTokens:聚合模式推理引擎最大批处理token数。
- aggregated.env:聚合模式推理引擎容器环境变量列表,用于配置该推理服务推理引擎Pod特殊需要的环境变量。
- aggregated.volumeMounts:聚合模式推理引擎容器volumeMounts列表,用于配置该推理服务推理引擎Pod特殊需要的volume挂载。
- aggregated.volumes:聚合模式推理引擎容器volumes列表,用于配置该推理服务推理引擎Pod特殊需要的volumes。
- aggregated.extraArgs:聚合模式推理引擎额外启动参数列表。
配置推理引擎资源
- resources.requests:推理引擎请求资源(如CPU、内存等)。
- resources.limits:推理引擎限制资源(如CPU、内存等)。
- inference-backend.images.inferenceEngine:配置推理引擎镜像(repository、tag)。InferNex默认配置使用
配置KVCache全局管理器参数。
配置是否启用KVCache全局管理器
- cache-indexer.enabled:cache-indexer为InferNex可选组件,默认为
true。
配置KVCache全局管理器的推理后端服务发现
cache-indexer.app.serviceDiscovery.labelSelector:对推理后端的自动服务发现的K8s Service资源标签。该标签在
inference-backend.service.openfuyao配置。示例:若推理后端K8s Service资源标签配置为:
yamllabels: openfuyao.com/engine: vllm inference-backend: "true"则该属性配置为
labelSelector: "inference-backend=true,openfuyao.com/engine=vllm"。cache-indexer.app.serviceDiscovery.refreshInterval:对推理后端的自动服务发现时间间隔(单位:秒)。
配置KVCache全局管理器的K8s服务
- cache-indexer.service.name:cache-indexer的K8s Service名称,默认为
cache-indexer-service。 - cache-indexer.service.port:cache-indexer的K8s Service端口,默认为
8080。
配置KVCache全局管理器镜像拉取
- cache-indexer.image.repository:cache-indexer镜像地址。
- cache-indexer.image.tag:cache-indexer镜像标签。
- cache-indexer.enabled:cache-indexer为InferNex可选组件,默认为
配置AI推理可观测参数。
配置是否开启AI推理可观测
- eagle-eye.enabled:控制是否启用AI推理可观测。
配置硬件健康检测镜像拉取
- hardware-monitor.images.core.repository:hardware-monitor镜像地址。
- hardware-monitor.images.core.tag:hardware-monitor镜像标签。
- hardware-monitor.images.core.pullPolicy:hardware-monitor镜像拉取策略。
配置硬件诊断镜像拉取
- hardware-diagnosis.images.core.repository:hardware-diagnosis镜像地址。
- hardware-diagnosis.images.core.tag:hardware-diagnosis镜像标签。
- hardware-diagnosis.images.core.pullPolicy:hardware-diagnosis镜像拉取策略。
配置是否开启prometheus监控K8s集群的套件
- kube-prometheus-stack.enabled:控制是否启用Prometheus监控K8s集群的功能。
配置PD-Orchestrator参数。
配置是否开启弹性扩缩容框架
- elastic-scaler.enabled: 控制是否启用elastic-scaler组件
配置弹性扩缩容框架镜像拉取
- elastic-scaler.images.repository:elastic-scaler镜像地址。
- elastic-scaler.images.tag:elastic-scaler镜像标签。
配置PD-Orchestrator组件安装命名空间
- elastic-scaler.namespace.name:PD-Orchestrator组件控制器所在的命名空间。
配置弹性扩缩容框架默认CR实例
elastic-scaler.elasticScaler.enabled:控制是否部署默认ElasticScaler CR实例。
elastic-scaler.targetRef.kind:默认ElasticScaler CR所控制的实际资源对象的类型,可以是kubernetes原生资源如
Deployment、StatefulSet等。在InferNex的配置中,该配置默认为resourcescalinggroup。elastic-scaler.targetRef.name:默认ElasticScaler CR所控制的实际资源对象的名字。在InferNex的配置中,该字段需要对应RSG资源对象的名称。示例:若RSG资源对象的配置为:
yamlresourcescalinggroup: instanceConfig: name: rsg则该属性需要配置为
elastic-scaler.targetRef.name:rsg。elastic-scaler.targetRef.apiVersion:默认ElasticScaler CR所控制的实际资源对象的API版本。在InferNex的配置中,该字段需要对应RSG资源对象的API版本,例如
autoscaling.openfuyao.com/v1alpha1。elastic-scaler.minReplicas:默认ElasticScaler CR所控制的实际资源对象的最小副本数量。
elastic-scaler.maxReplicas:默认ElasticScaler CR所控制的实际资源对象的最大副本数量。
elastic-scaler.trigger.scalingAlgorithm:触发实际资源对象扩缩的算法,默认配置为HPA。
elastic-scaler.trigger.resource.metricsName:触发实际资源对象扩缩的指标名称,默认配置为CPU,表示扩缩容模块会根据CPU指标进行资源副本数的计算。
elastic-scaler.trigger.resource.targetType:触发实际资源对象扩缩的指标类型,默认为利用率,与
elastic-scaler.trigger.resource.metricsName字段结合,表示CPU利用率是资源对象副本扩缩容的触发类型。elastic-scaler.trigger.resource.targetValue:触发实际资源对象扩缩的指标阈值。
配置是否开启PD扩缩资源管理对象组件
- resourcescalinggroup.enabled: 控制是否启用ResourceScalingGroup组件
配置PD扩缩资源管理对象组件镜像拉取
- resourcescalinggroup.images.repository:ResourceScalingGroup镜像地址。
- resourcescalinggroup.images.tag:ResourceScalingGroup镜像标签。
配置PD扩缩资源管理对象组件安装命名空间
- resourcescalinggroup.namespace.name:ResourceScalingGroup Controller部署所在的命名空间,默认是
scaling-system。 - resourcescalinggroup.namespace.create:是否自动创建
resourcescalinggroup.namespace.name指定的命名空间。若集群中不存在该命名空间,需要设置为true;否则需要提前手动创建。当前缺省值为false,默认不创建该命名空间。
配置PD扩缩资源管理对象组件运行参数
- resourcescalinggroup.prometheus.url:Prometheus查询地址,供
scaleDown.metric缩容策略使用,实际会注入环境变量RSG_PROMETHEUS_URL。该功能需搭配prometheus相关配置使用,详情请参考《资源组扩缩容》。
配置PD扩缩资源管理对象默认CR实例
ResourceScalingGroup CR实例配置
基础配置
resourcescalinggroup.instanceConfig.enabled:控制是否部署默认ResourceScalingGroup CR实例。
resourcescalinggroup.instanceConfig.name:默认ResourceScalingGroup CR实例的名字。
resourcescalinggroup.instanceConfig.scalingStrategy.type:默认ResourceScalingGroup CR实例采用的扩缩策略类型,为
GroupReplication或InplaceScaling。当前默认配置为GroupReplication,若需要改成InplaceScaling模式,请参考《资源组扩缩容》。resourcescalinggroup.instanceConfig.scalingStrategy.groupConfig.groupName:默认ResourceScalingGroup CR实例的组名前缀;为空时默认使用RSG名称。
resourcescalinggroup.instanceConfig.scalingStrategy.groupConfig.replicas:默认ResourceScalingGroup CR实例的期望组数,这个属性被
elastic-scaler.minReplicas和elastic-scaler.maxReplicas字段所限制。示例:若配置为:yamlelastic-scaler: minReplicas: 1 maxReplicas: 10则通过HPA扩缩容所创建的资源组数最少个数为1,最大个数为10。
resourcescalinggroup.instanceConfig.scalingStrategy.groupConfig.scaleDown.metric.expr:默认ResourceScalingGroup CR实例缩容参考的Prometheus指标表达式或指标名。
resourcescalinggroup.instanceConfig.scalingStrategy.groupConfig.scaleDown.metric.type:默认ResourceScalingGroup CR实例缩容指标类型,如
Counter、Gauge、Histogram。resourcescalinggroup.instanceConfig.scalingStrategy.groupConfig.scaleDown.metric.window:当缩容指标类型为
Counter或Histogram时使用的统计窗口。resourcescalinggroup.instanceConfig.scalingStrategy.groupConfig.scaleDown.metric.aggregator:缩容时对指标数据的聚合方式,如
avg、sum、max。resourcescalinggroup.instanceConfig.scalingStrategy.groupConfig.scaleDown.order:组缩容顺序,通常支持
ascending或descending。
扩缩资源对象配置
下面给出在InferNex的配置中,
resourcescalinggroup.instanceConfig.targetResources所有相关的字段的配置:yamlresourcescalinggroup: instanceConfig: name: rsg # ResourceScalingGroup CR实例的名字,需要和elastic-scaler.targetRef.name相同 targetResources: - name: prefill # 该名称用户可自定义 resourceRef: apiVersion: apps/v1 kind: Deployment # inference backend所创建的prefill节点的类型 name: vllm-pd-2p1d-01-prefill # 在InferNex的默认配置中,inference-backend.services.name配置为vllm-pd-2p1d-01,因此创建的prefill节点的Deployment资源名称为vllm-pd-2p1d-01-prefill一致。 - name: decode # 该名称用户可自定义 resourceRef: apiVersion: apps/v1 kind: Deployment # inference backend所创建的decode节点的类型 name: vllm-pd-2p1d-01-decode # 在InferNex的默认配置中,inference-backend.services.name配置为vllm-pd-2p1d-01,因此需和创建的decode节点的Deployment资源名称vllm-pd-2p1d-01-decode一致。resourcescalinggroup.instanceConfig.targetResources.name:默认ResourceScalingGroup CR实例中目标资源的逻辑名称,供缩放策略配置引用,组内必须唯一。
resourcescalinggroup.instanceConfig.targetResources.resourceRef.apiVersion:默认ResourceScalingGroup CR实例中目标工作负载的API版本。在InferNex的配置中,由于推理后端的默认配置对象是
Deployment,因此缺省值为apps/v1。resourcescalinggroup.instanceConfig.targetResources.resourceRef.kind:默认ResourceScalingGroup CR实例中目标工作负载类型,如
Deployment、StatefulSet、LeaderWorkerSet。在InferNex的配置中,缺省值为Deployment,该类型需要和inference-backend创建的推理后端资源类型相同。resourcescalinggroup.instanceConfig.targetResources.resourceRef.name:默认ResourceScalingGroup CR实例中目标工作负载名称。在InferNex的配置中,需要和
inference-backend.services.name所对应。resourcescalinggroup.instanceConfig.targetResources.resourceRef.namespace:默认ResourceScalingGroup CR实例中目标工作负载所在命名空间,为空时默认使用RSG所在命名空间。
配置是否开启潮汐算法组件
- tidal.enabled:控制是否启用TidalScheduler组件,用于按时间规则调整目标工作负载副本数或ResourceScalingGroup组数。
配置潮汐算法组件镜像配置
- tidal.images.repository:tidal镜像地址。
- tidal.images.tag:tidalr镜像标签。
说明:
TidalScheduler只负责根据时间规则计算期望副本数,实际扩缩容仍依赖ElasticScaler执行。若主要通过Tidal进行潮汐扩缩,建议保持elastic-scaler.enabled=true,并按需关闭默认ElasticScaler和ResourceScalingGroup的示例CR,避免与业务自定义的ElasticScaler或ResourceScalingGroup资源冲突。应用配置
用户参考安装章节部署以应用配置。
使用AI推理
前提条件
硬件要求
- 每个推理节点至少一张推理芯片。
- 每个推理节点至少32GB内存,4 CPU核。
- 在PD分离场景Mooncake传输KVCache时,若使用HCCS协议,宿主机
/etc/hccn.conf文件需要对宿主机的推理设备IP地址以及掩码配置正确,hccn.conf文件配置设备信息的示例脚本请参考昇腾HCCS设备IP地址配置示例。
软件要求
- Kubernetes v1.33.0及以上版本。
- 已安装npu-operator组件。
- 集群中需要安装metrics server v0.8.0及以上版本。
- 已经安装InferNex包含的必要组件:inference-backend、PD-Orchestrator。
网络要求
- 在PD分离场景Mooncake传输KVCache时,若使用HCCS协议跨机高速通信传输,需要有HCCS设备或者RDMA设备支持。
背景信息
无。
使用限制
- 当前仅支持vLLM/vLLM-Ascend推理引擎。
- 当前仅在Ascend910B4推理芯片验证。
- 当前仅支持AI推理场景,不支持AI训练场景。
- 当前仅支持Huggingface已有模型。
操作步骤
以release名称infernex和部署命名空间ai-inference为例:
获取服务访问地址。
1.1 查看hermes-router服务的访问地址:
bashkubectl get svc -n ai-inference1.2 记录网关的IP地址与端口。hermes-router服务名称为
inference-gateway-istio。发送推理请求(以curl发送请求为例)。
2.1 发送非流式推理请求:
bashcurl -X POST http://[路由服务IP地址]:[路由服务端口]/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{ "model": "Qwen/Qwen3-8B", "messages": [{"role": "user", "content": "请介绍openFuyao开源社区"}], "stream": false }'2.2 发送流式推理请求:
bashcurl -X POST http://[路由服务IP地址]:[路由服务端口]/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{ "model": "Qwen/Qwen3-8B", "messages": [{"role": "user", "content": "请介绍openFuyao开源社区"}], "stream": true }'接收推理结果。
3.1 非流式响应一次性返回完整结果。
3.2 流式响应逐块返回以
data:开头的JSON对象。
相关操作
以release名称infernex和命名空间ai-inference为例:
查看部署状态:
helm status infernex -n ai-inference卸载系统:
helm uninstall infernex -n ai-inference导出配置:
helm get values infernex -n ai-inference > current-values.yamlFAQ
Hermes-router以及Proxy Server初始阶段有错误信息。
现象描述: 通过查看Pod日志发现最初Hermes-router以及Proxy Server有很多报错的请求信息。
处理步骤: 正常现象。Hermes-router在初始化完毕后会定期向Proxy Server发送推理引擎指标查询请求,因推理引擎实例初始化时加载大模型耗时较长,此时指标查询请求无法被正确响应。等待推理引擎实例启动完毕后该问题不会出现。
Hermes-router以及cache-indexer无法发现推理服务。
现象描述: 通过查看Pod日志发现Hermes-router以及cache-indexer自动发现推理服务实例时报错。
处理步骤: 可能因为服务标签选择器配置错误。
hermes-router.app.discovery.labelSelector.app和cache-indexer.app.serviceDiscovery.labelSelector属性代表hermes-router以及cache-indexer对推理后端K8s Service资源的服务发现配置,需要与inference-backend.service.label属性一致。部署完成后网关无法正常工作。
现象描述: 安装完成后,Istio Envoy代理报错或无法将请求转发到后端服务,但后端推理服务运行状态正常。
处理步骤: 检查
HTTPRoute资源的parentRef.name是否与Gateway资源的名称一致(需与inferenceGateway.name配置项匹配)。PD分离模式下Decode服务没有正常使用Mooncake进行传输。
现象描述: PD分离架构部署后,Decode推理服务异常或性能不佳。
处理步骤: 检查Decode推理服务的prefix cache配置。在使用Mooncake进行传输的PD分离架构中,Decode推理服务不应启用prefix cache。请确认
pd.decode.enablePrefixCaching配置项设置为false,或使用--no-enable-prefix-caching参数启动Decode服务。PD分离模式下Decode服务一直在计算输出token,或推理请求结果为空字符串。
现象描述: 配置使用HCCS进行KVCache传输,PD分离架构部署后,Decode节点一直在计算返回token,输出不会停止。
处理步骤: 检查是否挂载宿主机的
hccn.conf文件,以及确认hccn.conf文件内是否对宿主机的推理设备IP地址以及掩码配置正确。hccn.conf文件配置设备信息的示例脚本请参考昇腾HCCS设备IP地址配置示例。使用非HuggingFace模型(如量化模型)导致推理引擎Pod无法部署。
现象描述: 用户使用非HuggingFace模型(如量化模型
Qwen3-8B-W4A8)时,推理引擎后端Pod在CrashLoopBackOff状态。处理步骤: 当前cache-indexer组件不兼容非Huggingface模型。将InferNex默认配置的
cache-indexer.enabled: true配置为cache-indexer.enabled: false,或将智能路由的路由策略修改为非kv-aware策略。推理后端组件可正常部署非HuggingFace模型。使用ResourceScalingGroup扩容的资源副本不会被helm uninstall删除。
现象描述: 使用ResourceScalingGroup时,若扩容出新的Deployment等资源,此时用户执行
helm uninstall命令卸载组件时,扩容出的Deployment等资源不会被删除。处理步骤: 在执行
helm uninstall命令前,执行以下命令,删除ResourceScalingGroup CR与扩容出的Deployment资源。bashkubectl delete resourcescalinggroup [rsg-name] -n [namespace] kubectl delete deployment -n [namespace] -l 'rsg.io/name=[rsg-name],rsg.io/group-id!=0'其中
rsg-name为CR实例的名称,namespace为实例所在的命名空间。
附录
自定义模型目录配置
当从HuggingFace上下载模型后,可以将模型文件放到自定义文件夹中。只需要确保挂载的文件夹格式为huggingface/hub/{模型目录},InferNex就能正常识别和使用该模型。例如,对于模型Qwen/Qwen3-8B,自定义文件夹结构应为:{缓存目录}/huggingface/hub/models--Qwen--Qwen3-8B(注意模型名字中的/会被转换为--)。配置global.cachePath时,只需指定到{缓存目录}即可,系统会自动识别huggingface/hub目录下的模型。
以下脚本示例为下载Qwen/Qwen3-8B模型到挂载目录/home/llm_cache/。
python3 -c "
import os
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = \"Qwen/Qwen3-8B\"
tokenizer = AutoTokenizer.from_pretrained(
model_name,
cache_dir='/home/llm_cache/huggingface/hub',
force_download=True,
resume_download=True # 断点续传
)
model = AutoModelForCausalLM.from_pretrained(
model_name,
cache_dir='/home/llm_cache/huggingface/hub',
force_download=True,
resume_download=True
)
"推理后端默认挂载配置
InferNex默认配置了推理后端的volumeMounts和volumes,包括Ascend设备相关的挂载。以下是默认配置示例:
默认volumeMounts:
volumeMounts:
ascend: # Ascend 设备相关的 volumeMounts
enable: true # 是否启用 Ascend 相关的 volumeMounts
mounts:
- name: shm
mountPath: /dev/shm
- name: dcmi
mountPath: /usr/local/dcmi
- name: npusmi
mountPath: /usr/local/bin/npu-smi
- name: lib64
mountPath: /usr/local/Ascend/driver/lib64
- name: version
mountPath: /usr/local/Ascend/driver/version.info
- name: installinfo
mountPath: /etc/ascend_install.info
- name: hccntool
mountPath: /usr/bin/hccn_tool
- name: hccnconf
mountPath: /etc/hccn.conf默认volumes:
volumes:
ascend: # Ascend 设备相关的 volumes
enable: true # 是否启用 Ascend 相关的 volumes
mounts:
- name: shm
emptyDir:
medium: Memory
sizeLimit: "24Gi"
- name: dcmi
hostPath:
path: /usr/local/dcmi
- name: npusmi
hostPath:
path: /usr/local/bin/npu-smi
type: File
- name: lib64
hostPath:
path: /usr/local/Ascend/driver/lib64
- name: version
hostPath:
path: /usr/local/Ascend/driver/version.info
type: File
- name: installinfo
hostPath:
path: /etc/ascend_install.info
type: File
- name: hccntool
hostPath:
path: /usr/bin/hccn_tool
type: File
- name: hccnconf
hostPath:
path: /etc/hccn.conf
type: File昇腾HCCS设备IP地址配置示例
以下脚本示例展示了如何为多张Ascend设备配置hccn.conf中的设备IP地址和掩码信息,可根据实际设备数量和网络规划进行调整:
#!/bin/bash
for i in {0..7}
do
hccn_tool -i $i -ip -s address 192.168.102.$i netmask 255.255.255.0
done离线包制作指南
获取在线chart包。
1.1 从openFuyao官方镜像仓库获取项目安装包:
bashhelm pull oci://cr.openfuyao.cn/charts/infernex --version xxx其中
xxx需替换为具体项目安装包版本,如0.22.1。拉取得到的安装包为压缩包形式。1.2 解压安装包:
bashtar -xzvf infernex-xxx.tgz其中
xxx需替换为具体项目安装包版本,如0.22.1。修改
values.yaml配置文件。在解压后的chart包文件
infernex中找到values.yaml文件,进行以下配置修改:- 将
global.image.pullPolicy的值改为Never,使系统使用本地镜像而非从远程仓库拉取。 - 将
global.env中的HF_HUB_OFFLINE环境变量值设置为1,启用HuggingFace离线模式,防止推理引擎启动时向Huggingface请求下载模型。
- 将
添加镜像文件。
将所需镜像通过
nerdctl save命令压缩为tar.gz格式文件:bashnerdctl save -o xxx.tar.gz xxxInferNex 0.22.1版本离线包默认镜像列表:
- cr.openfuyao.cn/openfuyao/eagle-eye-hardware-diagnosis:0.22.0
- cr.openfuyao.cn/openfuyao/eagle-eye-hardware-monitor:0.22.0
- cr.openfuyao.cn/openfuyao/npu-exporter:v7.2.RC1-of.1
- cr.openfuyao.cn/openfuyao/hermes-router:0.21.0
- cr.openfuyao.cn/openfuyao/cache-indexer:0.21.1
- cr.openfuyao.cn/openfuyao/huggingface-download:0.22.1
- hub.oepkgs.net/openfuyao/redis:8.6.1
- hub.oepkgs.net/openfuyao/mikefarah/yq:4.50.1
- cr.openfuyao.cn/openfuyao/elastic-scaler:0.20.0
- cr.openfuyao.cn/openfuyao/resource-scaling-group:0.20.0
- cr.openfuyao.cn/openfuyao/tidal:0.20.0
- hub.oepkgs.net/openfuyao/alpine/kubectl:1.34.2
- hub.oepkgs.net/openfuyao/prometheus/node-exporter:v1.8.2
- hub.oepkgs.net/openfuyao/kube-state-metrics/kube-state-metrics:v2.14.0
- hub.oepkgs.net/openfuyao/prometheus/alertmanager:v0.28.0
- hub.oepkgs.net/openfuyao/prometheus-operator/admission-webhook:v0.80.0
- hub.oepkgs.net/openfuyao/ingress-nginx/kube-webhook-certgen:v1.5.1
- hub.oepkgs.net/openfuyao/prometheus-operator/prometheus-operator:v0.80.0
- hub.oepkgs.net/openfuyao/prometheus-operator/prometheus-config-reloader:v0.80.0
- hub.oepkgs.net/openfuyao/thanos/thanos:v0.37.2
- hub.oepkgs.net/openfuyao/prometheus/prometheus:v3.1.0
- hub.oepkgs.net/openfuyao/nats:2.12.1-alpine
- hub.oepkgs.net/openfuyao/natsio/nats-server-config-reloader:0.20.1
- hub.oepkgs.net/openfuyao/natsio/prometheus-nats-exporter:0.17.3
- hub.oepkgs.net/openfuyao/busybox:1.36.1
- hub.oepkgs.net/openfuyao/istio/pilot:1.28.0
- hub.oepkgs.net/openfuyao/istio/proxyv2:1.28.0
- hub.oepkgs.net/openfuyao/ascend/vllm-ascend:v0.13.0
添加本地模型文件。
按照自定义模型目录配置的说明将模型文件下载,并配置
global.cachePath参数指向模型目录。制作离线包。
将以下内容打包制作成离线安装包:
- chart包文件:包含修改后的
values.yaml配置文件。 - 镜像文件:通过
nerdctl save命令压缩的镜像tar.gz文件。 - 模型缓存文件:压缩后的模型目录文件。
- chart包文件:包含修改后的
AI推理软件套件模式部署
在openFuyao v26.03版本中,AI推理软件套件(AI inference software suite)相关功能已经合并到Infernex中并继续演进。AI推理软件套件原定位为面向一体机场景的轻量化推理软件部署方案,基于openFuyao平台应用市场实现一键安装部署,支持鲲鹏、昇腾亲和及主流CPU计算场景。合并后,用户可通过InferNex的配置项以聚合模式部署推理引擎,实现与原AI推理软件套件等价的轻量化推理部署能力。
以下提供原AI推理软件套件的核心规格及向InferNex的迁移指南。
原AI推理软件套件规格概览
- 应用场景:Web场景和API接口场景,支持通过openAI API调用大模型推理能力。
- 部署方式:通过openFuyao平台应用市场一键部署
aiaio-installer应用。 - 核心组件:NPU Operator(或GPU Operator)、KubeRay Operator。
- 推理引擎:基于vLLM,支持vLLM v1版本。
- 硬件支持:昇腾910B/910B4、NVIDIA V100。
- 模型支持:HuggingFace已有模型,如DeepSeek-R1-Distill系列(1.5B~70B)。
- API接口:遵循openAI API规范,提供
/v1/chat/completions接口。
迁移指南
从AI推理软件套件迁移到InferNex,主要涉及部署方式和配置方式的变更,推理API接口保持兼容。
- 部署方式变更
原AI推理软件套件通过openFuyao平台应用市场一键部署aiaio-installer应用,迁移后使用InferNex Helm Chart部署。具体部署步骤请参考安装章节。
- 配置参数映射
原AI推理软件套件的values.yaml配置参数与InferNex配置参数的对应关系如下:
表1 AI推理软件套件与Infernex配置参数映射
| 原AI推理软件套件参数 | InferNex配置参数 | 说明 |
|---|---|---|
| accelerator.NPU / accelerator.GPU | inference-backend.inferenceDevice | 指定推理芯片类型,NPU对应huawei.com/Ascend910,GPU暂不支持。 |
| accelerator.type | - | 当前Infernex暂时仅支持NPU。 |
| accelerator.num | - | Infernex支持自动计算需要的加速器数量。 |
| service.model | global.modelName | 推理模型名称。 |
| service.tensor_parallel_size | aggregated.tensorParallelSize | 张量并行度。 |
| service.pipeline_parallel_size | aggregated.pipelineParallelSize | 流水线并行度。 |
| service.max_model_len | aggregated.maxModelLen | 模型最大序列长度。 |
| service.vllm_use_v1 | - | InferNex默认使用vLLM v1引擎。 |
| storage.size | - | 当前Infernex支持直接挂载host目录,无需填写。 |
- 模型推荐配置映射
以下为原AI推理软件套件模型推荐配置在InferNex中的对应配置示例:
表2 AI推理软件套件推荐配置与Infernex配置对应表
| 模型规模 | global.modelName | aggregated.tensorParallelSize | aggregated.pipelineParallelSize | 推荐存储大小 |
|---|---|---|---|---|
| 1.5B | deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B | 1 | 1 | 10Gi |
| 7B | deepseek-ai/DeepSeek-R1-Distill-Qwen-7B | 1 | 1 | 20Gi |
| 8B | deepseek-ai/DeepSeek-R1-Distill-Llama-8B | 1 | 1 | 25Gi |
| 14B | deepseek-ai/DeepSeek-R1-Distill-Qwen-14B | 2 | 1 | 40Gi |
| 32B | deepseek-ai/DeepSeek-R1-Distill-Qwen-32B | 4 | 1 | 80Gi |
| 70B | deepseek-ai/DeepSeek-R1-Distill-Llama-70B | 8 | 1 | 160Gi |
- API接口兼容性
迁移后推理API接口保持兼容,仍遵循openAI API规范。用户可通过InferNex部署的推理服务地址访问/v1/chat/completions接口,请求和响应格式与原AI推理软件套件一致。具体使用方式请参考使用AI推理章节。
原AI推理软件套件使用的aiaio-installer应用在v26.03版本后不再维护。如需使用一体机场景的轻量化推理部署能力,请使用InferNex聚合模式部署。
配置示例
本节给出使用Infernex部署DeepSeek-R1-Distill-Qwen-7B的配置文件,该文件同时可在openFuyao/InferNex仓库的examples/ai_software_suite目录中获取。
inferenceGateway:
enabled: false
global:
image:
pullPolicy: IfNotPresent
imagePullSecrets: [] # 私有镜像仓库的 Secret,例如: [{"name": "registry-secret"}]
env:
- name: HF_HUB_OFFLINE # HuggingFace Hub 离线开关(1=离线;0=在线)
value: "0"
modelName: "deepseek-ai/DeepSeek-R1-Distill-Qwen-7B" # 推理模型名称
cachePath: "/home/llm_cache" # 推理侧缓存目录(如 HuggingFace / vLLM 的下载与编译缓存)
hermes-router:
enabled: false
inference-backend:
images:
inferenceEngine:
repository: "hub.oepkgs.net/openfuyao/ascend/vllm-ascend"
tag: "v0.13.0"
proxyServer:
repository: "cr.openfuyao.cn/openfuyao/proxy-server"
tag: "latest"
inferenceDevice: "huawei.com/Ascend910"
services:
- name: vllm-aggregated-tp2-01
enabled: true
mode: aggregated # 推理后端使用聚合模式
service:
port: 8000
aggregated:
replicas: 1
enablePrefixCaching: true
tensorParallelSize: 2
pipelineParallelSize: 1
dataParallelSize: 1
gpuMemoryUtilization: 0.8
blockSize: 128
maxModelLen: 10000
maxNumBatchedTokens: 40960
extraArgs: [] # aggregated 节点额外的 vLLM 启动参数,例如: ["--dtype float16", "--max-num-seqs 256"]
resources: # aggregated 节点资源配置
requests:
cpu: "4"
memory: "32Gi"
limits:
cpu: "8"
memory: "64Gi"
# cache indexer
cache-indexer:
enabled: false
eagle-eye:
enabled: false
pd-orchestrator:
elastic-scaler:
enabled: false
resourcescalinggroup:
enabled: false
tidal:
enabled: false遵循 木兰宽松许可证第2版(MulanPSL2)
