AI推理赫尔墨斯路由
特性介绍
Hermes-router是一个Kubernetes(K8s)原生的AI推理智能路由方案,用于接收用户推理请求并转发至合适的推理服务后端。
- 在架构上,Hermes-router遵从K8s gateway api inference extension(GIE)框架,是一个可插拔、可扩展的EndPointPicker(EPP)组件,最大程度兼容K8s生态。
- 在能力上,Hermes-router提供KVCache aware、PD分桶调度等多种AI推理路由策略,帮助用户在多种云原生场景下提升AI推理性能、集群资源利用率与服务稳定性。
应用场景
Hermes-router适用于在Kubernetes集群环境中部署和运行AI推理服务,具体包括如下场景。
- 云原生AI推理服务:在K8s集群中部署大语言模型(LLM)推理服务,需要智能路由能力来优化请求分发和资源利用。
- 多实例推理后端:需要将推理请求智能路由到多个推理服务实例(支持聚合架构或PD分离架构),实现负载均衡和性能优化。
- 高并发推理场景:在长短请求混合、中高并发的业务场景中,需要根据请求特征和实例负载状态进行智能调度,提升推理吞吐量。
- KVCache aware优化场景:在重复请求较多的场景中,需要利用KVCache命中率信息进行路由优化,提升推理性能和资源利用率。
- 网关集成场景:已有K8s网关基础设施,需要在不影响原有网关的基础上,增加AI推理路由能力。
能力范围
- 支持用户在K8s集群部署使用。
- 支持用户配置多种路由策略,进行openAI API风格的AI推理请求。
软件依赖
Hermes-router作为GIE框架的EPP组件,需与支持Gateway API Inference Extension的开源网关配合使用。下表列出了可选开源网关及其依赖组件的版本要求。
表1 可选开源网关与依赖组件版本
| 网关 | 网关版本 | Gateway API | GIE | Kubernetes |
|---|---|---|---|---|
| Istio | 1.27+ | 1.4.0+ | 1.0+ | 1.29+ |
| Nginx Gateway Fabric | 2.2+ | 1.3.0+ | 1.0+ | 1.25+ |
| Envoy AI Gateway | 0.4+ | 1.4.0+ | 1.0+ | 1.32+ |
| Kgateway | 2.1+ | 1.3.0+ | 1.0+ | 1.29+ |
说明:
表中为已验证兼容的最低版本,推荐使用最新版本的开源网关以确保体验。
亮点特征
这里主要列举独立于GIE框架的亮点。
- 特性设计遵循GIE框架,天然支持K8s网关体系,支持集成多种开源网关,在已有网关的集群,可以作为可插拔能力加入,在不影响原有网关的基础上增加AI推理路由能力。
- 提供多种创新路由策略,支持聚合、PD等推理后端架构,帮助使用者在多种业务场景中提升性能。
- KVCache aware(聚合/PD):提供允许用户自定义得分函数的KVCache aware路由策略,在重复请求场景提升推理性能。
- PD分桶调度路由 (PD):提供允许用户自定义参数的分桶调度策略,在长短请求、中高并发场景提升推理吞吐量。
- 动态推理服务发现:允许用户在运行时新增/删除推理后端,允许用户灵活调整推理资源投入。
实现原理
图1 Hermers-router架构 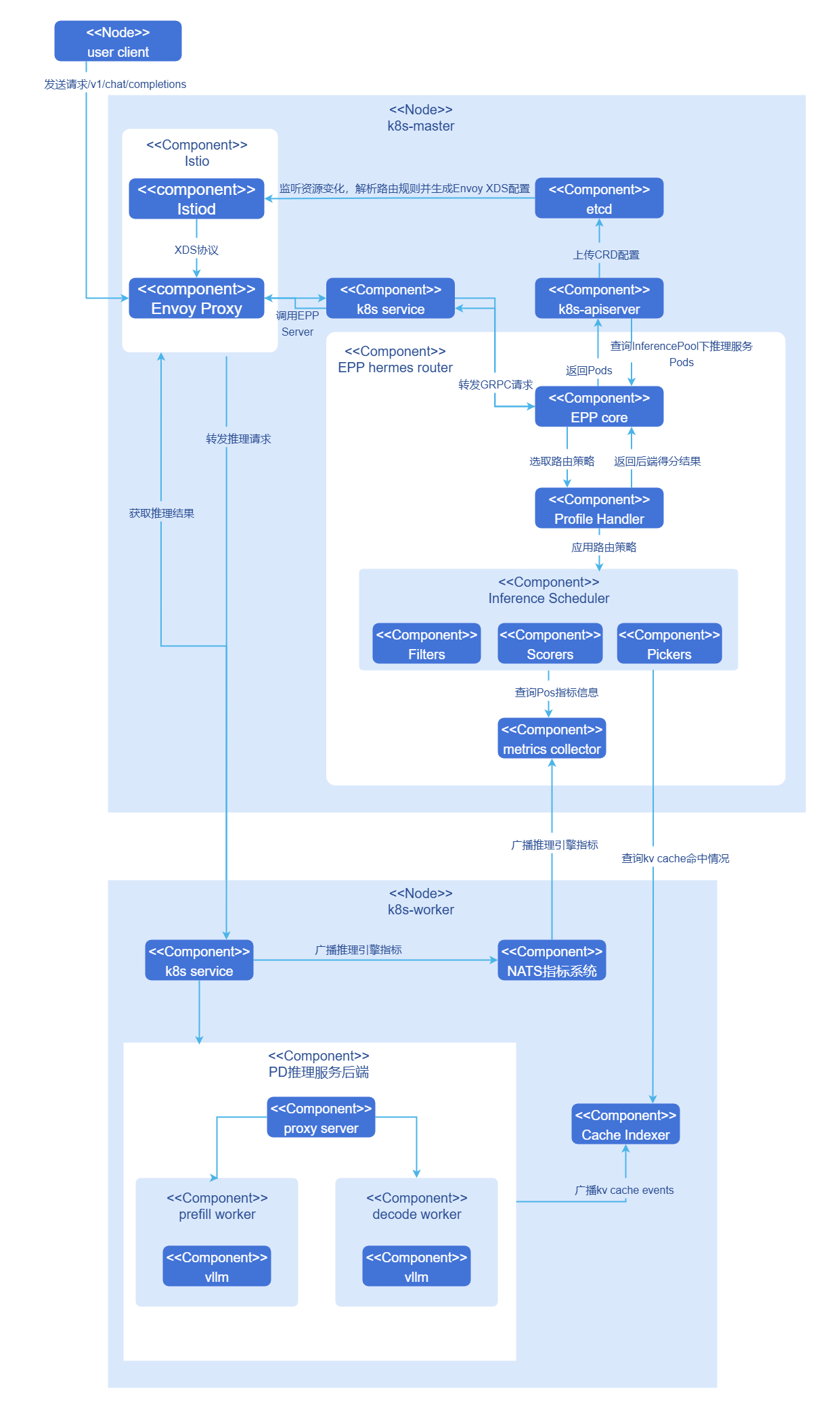
Hermes-router以EPP组件形式集成到开源网关,下面以一次完整推理请求为例说明内部原理。
- 用户向集群网关发送openAI API请求
/v1/chat/completions。 - 网关识别到请求为推理请求,将请求转发至EPP。
- EPP根据用户配置的路由策略处理请求,选出最适合处理该推理请求的推理后端。
- EPP将推理后端返回集群网关,集群网关将推理请求发送至目标推理后端。
- 推理后端完成请求返回网关,网关将推理结果返回用户。
与相关特性的关系
- cache-indexer:使用KVCache aware类型策略时依赖,通过
/match_sort接口从该组件获取KVCache命中率。 - vLLM-ascend:对于该特性有以下具体依赖。
- PD代理服务组件
proxy-server:原为vllm官方在PD分离架构下提供的示例组件,作为中枢组织P/D实例完成推理任务,openFuyao社区对该组件进行增强,现作为PD Group的Leader实例接收网关推理请求,并具备根据指定标签动态发现推理服务实例的能力。 - NPU适配:当环境为昇腾NPU时,需要使用vLLM-ascend作为推理引擎启动服务。
- 推理指标:依赖vllm提供的
/metrics接口获取推理服务指标,由GIE架构自动获取。
- PD代理服务组件
安装
EPP组件单独部署
本节介绍如何在已有Kubernetes Gateway基础设施的集群中,单独部署Hermes-router作为EPP组件。
交付规格
Hermes-router作为单独的EPP组件部署到集群中,需要集群中已有Envoy based的Gateway、Gateway API及Inference Extension CRDs、以及推理后端服务。Hermes-router部署后提供多种AI推理智能路由策略(KVCache aware、PD分桶调度等),通过InferencePool CR动态发现和管理推理后端,支持通过HTTPRoute进行灵活配置。
前提条件
在开始安装前,请确保满足以下条件。
环境要求
- Kubernetes集群:v1.33.0及以上版本。
- 集群管理员权限:用于安装CRD和集群级资源。
- Helm工具:用于部署Hermes router和相关组件。
部署组件要求
部署Hermes-router之前,集群中需要已安装以下组件。
- Envoy based网关:集群中已部署支持ExtProc协议的网关(如Istio、Envoy Gateway等),Hermes-router通过ExtProc(gRPC)与网关交互。
- Gateway API CRDs:已安装Kubernetes Gateway API核心资源定义。
- Inference Extension CRDs:已安装Gateway API Inference Extension,提供InferencePool等推理扩展资源定义。
- 推理后端服务:集群中已部署vLLM等推理引擎服务。
说明:
如果集群中尚未安装上述组件,请参考安装配套组件章节完成安装。硬件要求
Hermes-router本身对硬件环境无特殊要求,作为轻量级路由组件,可运行在标准x86或ARM架构的节点上。
快速安装Hermes router
Hermes-router支持多种路由策略,用户可根据业务场景从openFuyao GitCode仓库获取chart包和预置的路由策略配置文件。
从仓库拉取项目。
bashgit clone https://gitcode.com/openFuyao/hermes-router.git安装部署。
以release名称
hermes-router为例,在hermes-router同级目录下执行如下命令。bashcd hermes-router/charts/hermes-router helm dependency build helm install -n <NAMESPACE> hermes-router . \ -f <路由策略文件名>参数说明如下。
<NAMESPACE>:部署的目标命名空间(如ai-inference)。<路由策略文件名>:直接使用表2中的策略文件;仓库已在examples/profiles/目录提供示例(见profiles目录),可按需复用或自定义。
表2 预置路由策略列表
策略文件 策略名称 适用场景 说明 epp-random-pd-bucket.yaml随机PD分桶路由 简单负载均衡 随机选择PD Bucket,实现基础的负载均衡。 epp-pd-bucket.yamlPD分桶调度路由 基于负载的路由 根据PD Bucket的负载状态进行评分,选择最优实例,支持TP异构的PD分离架构。 epp-pd-kv-cache-aware.yamlPD KVCache感知路由 PD架构下的KVCache优化 结合KVCache命中率、XPU缓存使用率等信息,智能选择最优推理服务(适用于PD架构)。 epp-kv-cache-aware.yaml聚合架构KVCache感知路由 聚合架构下的KVCache优化 结合KVCache命中率、XPU缓存使用率和等待请求数等信息,智能选择最优推理服务(适用于聚合架构)。 验证部署。
bash# 检查Pod运行状态 kubectl get pods -n <NAMESPACE> -l inferencepool=<INFERENCEPOOL_NAME>-epp # 检查InferencePool资源 kubectl get inferencepool -n <NAMESPACE> # 检查HTTPRoute资源 kubectl get httproute -n <NAMESPACE>
EPP Pod的label格式为inferencepool=<INFERENCEPOOL_NAME>-epp,其中<INFERENCEPOOL_NAME>为InferencePool资源的名称,对应values.yaml中的.Values.inferencepool.name配置项。例如,如果InferencePool名称为vllm-qwen-qwen3-8b,则EPP Pod的label为app=vllm-qwen-qwen3-8b-epp。
注意:
部署Hermes router时需要正确配置HTTPRoute和InferencePool CR。
- HTTPRoute需要通过parentRef关联到集群中的Gateway资源。
- InferencePool需要配置正确的标签选择器(matchLabels),以发现和管理推理后端实例。
- 路由策略的详细配置请参考配置路由策略章节。
InferNex集成部署
本节介绍如何通过Infernex集成部署Hermes-router。
交付规格
InferNex是完整的AI推理服务集成部署包,一键部署网关、Hermes-router、HTTPRoute/InferencePool等K8s资源、以及推理后端服务。提供端到端的AI推理解决方案,集成网关、智能路由和推理服务,开箱即用。
当环境中尚无网关和推理后端且需要开箱部署时,可直接使用InferNex完成集成部署,参考安装与配置指南。
前提条件
- Kubernetes v1.33.0及以上版本。
- Kubernetes Gateway API CRDs:提供Gateway API的核心资源定义。
- Gateway API Inference Extension CRDs:提供InferencePool等推理扩展资源定义。
- 每个推理节点至少一张推理芯片。
- 每个推理节点至少16GB内存,4CPU核。
- 在线安装能够访问镜像仓库:oci://cr.openfuyao.cn。
- 用户具备创建RBAC资源的权限。
快速安装InferNex
InferNex有以下两种途径独立部署。
从openFuyao官方镜像仓库获取项目安装包。
拉取项目安装包。
bashhelm pull oci://cr.openfuyao.cn/charts/infernex --version xxx其中
xxx需替换为具体项目安装包版本,如0.21.1。拉取得到的安装包为压缩包形式。解压安装包。
bashtar -xzvf infernex-xxx.tgz其中
xxx需替换为具体项目安装包版本,如0.21.1。安装部署。
以release名称
infernex为例,执行安装前请确保完成如下操作。- 集群已创建命名空间
istio-system(Istio Gateway资源必须部署在此命名空间)。 - 集群已创建
values.yaml中global.namespace配置项指定的命名空间。其他组件(如inference-backend、hermes-router、cache-indexer等)的命名空间可通过values.yaml中的global.namespace配置项进行设置,缺省值为ai-inference。
在
infernex同级目录下执行如下命令。bashhelm install -n istio-system infernex ./infernex- 集群已创建命名空间
从openFuyao GitCode仓库获取。
从仓库拉取项目。
bashgit clone https://gitcode.com/openFuyao/InferNex.git安装部署。
以release名称
infernex为例,helm安装时由于集成开源网关istio,需要指定命名空间istio-system,其他组件的命名空间设定可在values.yaml中的global.namespace进行配置。在InferNex同级目录下执行如下命令。bashcd InferNex/charts/infernex helm dependency build helm install -n istio-system infernex .
安装配套组件
如果您的集群中尚未部署网关、推理后端等配套组件,请按照本节内容完成安装。
开源网关安装
Hermes-router需要配合支持Kubernetes Gateway API和Gateway API Inference Extension的开源网关使用。本文档以Istio为例介绍安装部署流程。
安装Istio并启用Gateway API Inference Extension支持。
bashistioctl install -y \ --set tag=<ISTIO_TAG> \ --set hub=gcr.io/istio-testing \ --set values.pilot.env.ENABLE_GATEWAY_API_INFERENCE_EXTENSION=true⚠️注意:
ISTIO_TAG需要使用支持Inference Extension的Istio版本。可执行curl -s https://storage.googleapis.com/istio-build/dev/1.28-dev获取其最新版本。验证安装。
验证Istio安装。
shellkubectl get pods -n istio-system部署Inference Gateway。
完成基础设施安装后,可以部署Inference Gateway。
shellhelm upgrade --install inference-gateway examples/1_pd_bucket/charts/gateway \ -n <NAMESPACE> --create-namespace \ --set gateway.className=istio
开源网关注意事项如下。
- Istio版本:需要使用支持Inference Extension的Istio开发版本,稳定版本可能不支持。
- 权限要求:安装CRDs需要集群管理员权限。
- 其他开源网关:除了Istio,用户可以根据自己需要选择支持Gateway API和Gateway API Inference Extension的开源网关,配置时只需将
gateway.className设置为对应的GatewayClass名称即可。
推理引擎后端安装
Hermes-router目前支持vLLM推理引擎,提供聚合与PD分离两种架构,用户可按需选择部署。
按照聚合架构(Aggregated)安装,执行如下命令。
shellhelm upgrade --install vllm examples/2_kv_aware/charts/vllm \ -n ${NAMESPACE} --create-namespace \ --set modelServer.name=$(MODEL) \ --set modelServer.rootCachePath=/home/llm_cache按照PD分离架构(Prefill-Decode Disaggregated)安装,执行如下命令。
shellhelm upgrade --install vllm-pd examples/1_pd_bucket/charts/vllm-pd \ -n ${NAMESPACE} --create-namespace \ --set modelServer.name=$(MODEL) \ --set modelServer.rootCachePath=/home/llm_cache
在vLLM分离架构部署中,代理服务器需能解析EPP路由新增的请求头,以实现向P端和D端后端服务的精准路由。具体实现可参考:proxy_server_example。
安装cache-indexer(可选)
Hermes-router在使用KVCache aware路由策略时必须安装cache-indexer组件,以获取全局KV Cache信息,安装步骤如下。
获取openFuyao/cache-indexer组件helm chart部署包。
shellhelm fetch oci://cr.openfuyao.cn/charts/cache-indexer --version 0.20.0配置cache-indexer以正确提供全局KVCache hit rate计算服务。在上一步获取的helm chart中打开
charts/cache-indexer/values.yaml文件进行配置,下面对必须配置的参数进行说明。yamlapp: serviceDiscovery: # 该类配置用于动态发现推理服务实例,并订阅kv cache消息 labelSelector: "openfuyao.com/model=qwen-qwen3-8b" # 动态发现携带此标签的推理实例Pod portName: "zmq-pub" # 向名称为此值的vllm port中订阅kv cache消息; refreshInterval: 10 # 订阅间隔(s) service: name: cache-indexer-service # 运行时service资源的名称,hermes-router通过该名称请求cache-indexer port: 8080 # 对外端口 # ... 其他配置部署cache-indexer。
shellhelm upgrade --install cache-indexer ./charts/cache-indexer \ -n ${NAMESPACE} --create-namespace检查部署结果。
确认Pod运行正常,且日志显示已成功发现推理服务后端实例。
使用AI推理服务
部署完成后,可以通过如下两种方式向Inference Gateway发送推理请求。
LoadBalancer访问
如果集群支持LoadBalancer,Istio Gateway会自动创建LoadBalancer类型的Service。
shell# 获取External IP EXTERNAL_IP=$(kubectl get svc -n istio-system istio-ingressgateway -o jsonpath='{.status.loadBalancer.ingress[0].ip}')发送推理请求。
shellcurl -X POST http://${EXTERNAL_IP}/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{ "model": "Qwen/Qwen3-8B", "messages": [ {"role": "user", "content": "你好"} ], "max_tokens": 100, "temperature": 0.7, "stream": false }'
NodePort访问
执行如下命令,获取节点IP地址和端口。
shellkubectl get svc -n istio-system istio-ingressgateway查看PORT(S)列,例如80:30080/TCP,其中30080是NodePort。
如果没有ExternalIP,使用InternalIP。
shellNODE_IP=$(kubectl get nodes -o jsonpath='{.items[0].status.addresses[?(@.type=="InternalIP")].address}') NODE_PORT=$(kubectl get svc -n istio-system istio-ingressgateway -o jsonpath='{.spec.ports[?(@.port==80)].nodePort}')发送请求。
shellcurl -X POST http://${NODE_IP}:${NODE_PORT}/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{ "model": "Qwen/Qwen3-8B", "messages": [ {"role": "user", "content": "你好"} ], "max_tokens": 100, "temperature": 0.7, "stream": false }'
配置路由策略
指标映射
当使用vLLM-Ascend在NPU环境运行时,需要对指标名称进行映射。默认情况下,GIE框架使用的kv-cache-usage-percentage-metric为GPU环境下vLLM的指标名称。为适配vLLM-Ascend,需要通过flags将该指标映射为vLLM-Ascend使用的vllm:kv_cache_usage_perc,配置如下:
inferenceExtension:
flags:
kv-cache-usage-percentage-metric: "vllm:kv_cache_usage_perc"该配置会将GIE框架采集到的指标kv-cache-usage-percentage-metric映射为vllm:kv_cache_usage_perc,以便后续路由策略基于正确的指标名称进行计算。
aggregate kv cache aware
inferenceExtension:
pluginsConfigFile: "epp-aggregate-kv-cache-aware.yaml"
pluginsCustomConfig:
epp-aggregate-kv-cache-aware.yaml: |
apiVersion: inference.networking.x-k8s.io/v1alpha1
kind: EndpointPickerConfig
plugins:
- type: scorer-aggregate-kv-cache-aware # 评分插件
parameters: # 评分参数
kvCacheHitNotRateWeight: 1.0
xpuCacheUsageWeight: 1.0
waitingRequestWeight: 1.0
kvCacheManagerIP: cache-indexer-service
kvCacheManagerPort: 8080
kvCacheManagerPath: /match_sort
kvCacheManagerTimeout: 5000000000
- type: picker-min-random # 选择器插件
schedulingProfiles:
- name: default
plugins:
- pluginRef: scorer-aggregate-kv-cache-aware
- pluginRef: picker-min-random插件说明如下。
scorer-aggregate-kv-cache-aware:根据KVCache命中率、XPU缓存使用率和等待请求数对推理服务实例进行评分。
picker-min-random:从评分最低的实例中随机选择一个,实现负载均衡。
表3 KVCache aware agg参数说明
| 参数 | 类型 | 说明 | 缺省值 |
|---|---|---|---|
kvCacheHitNotRateWeight | float | KVCache未命中率权重。 | 1.0 |
xpuCacheUsageWeight | float | XPU缓存使用率权重。 | 1.0 |
waitingRequestWeight | float | 等待请求数权重。 | 1.0 |
kvCacheManagerIP | string | KVCache Indexer服务IP地址/名称。 | cache-indexer-service |
kvCacheManagerPort | int | KVCache Indexer服务端口。 | 8080 |
kvCacheManagerPath | string | KVCache Indexer API路径。 | /match_sort |
kvCacheManagerTimeout | int | KVCache Indexer请求超时(纳秒)。 | 5000000000 |
权重参数说明如下。
- 增大权重:该指标在评分中的影响更大。
- 减小权重:该指标的影响降低。
- 示例:如果更关注KVCache命中率,可增大
kvCacheHitNotRateWeight。
pd kv cache aware
inferenceExtension:
pluginsConfigFile: "epp-pd-kv-cache-aware.yaml"
pluginsCustomConfig:
epp-pd-kv-cache-aware.yaml: |
apiVersion: inference.networking.x-k8s.io/v1alpha1
kind: EndpointPickerConfig
plugins:
- type: filter-by-pd-label # PD标签过滤插件
- type: scorer-pd-kv-cache-aware # PD KV Cache 感知评分插件
- type: picker-pd-kv-cache-aware # PD KV Cache 感知选择器
- type: pd-header-handler # PD请求头处理插件
schedulingProfiles:
- name: default
plugins:
- pluginRef: filter-by-pd-label
- pluginRef: scorer-pd-kv-cache-aware
- pluginRef: picker-pd-kv-cache-aware
- pluginRef: pd-header-handlerpd kv cache aware策略使用的插件如下。
filter-by-pd-label:根据PD角色(Prefill/Decode)和分组ID过滤推理服务实例。
scorer-pd-kv-cache-aware:结合KVCache命中率、XPU缓存使用率和等待请求数,对Prefill和Decode Pod分别评分。
picker-pd-kv-cache-aware:根据评分结果,智能选择最优的Prefill或Decode Pod。
pd-header-handler:添加PD分离架构所需的请求头信息,用于指定路由后端。
其中filter-by-pd-label、scorer-pd-kv-cache-aware两个插件的参数说明如表4、表5所示。
表4 filter-by-pd-label参数说明
| 参数 | 类型 | 说明 | 缺省值 |
|---|---|---|---|
pdLabelName | string | PD角色标签名称。 | openfuyao.com/pdRole |
pdGroupLabelName | string | PD分组标签名称。 | openfuyao.com/pdGroupID |
prefillValue | string | Prefill角色标签值。 | prefill |
decodeValue | string | Decode角色标签值。 | decode |
leaderValue | string | Leader角色标签值。 | leader |
表5 scorer-pd-kv-cache-aware参数说明
| 参数 | 类型 | 说明 | 缺省值 |
|---|---|---|---|
kvCacheHitNotRateWeight | float | KVCache未命中率权重。 | 1.0 |
xpuCacheUsageWeight | float | XPU缓存使用率权重。 | 1.0 |
prefillWaitingRequestWeight | float | Prefill等待请求数权重。 | 1.0 |
decodeWaitingRequestWeight | float | Decode等待请求数权重。 | 1.0 |
prefillPodScoreWeight | float | Prefill Pod评分权重。 | 1.0 |
decodePodScoreWeight | float | Decode Pod评分权重。 | 1.0 |
kvCacheManagerIP | string | KVCache Indexer服务IP地址/名称。 | cache-indexer-service |
kvCacheManagerPort | int | KVCache Indexer服务端口。 | 8080 |
kvCacheManagerPath | string | KVCache Indexer API路径。 | /match_sort |
kvCacheManagerTimeout | int | KVCache Indexer请求超时(纳秒)。 | 5000000000 |
PD标签配置说明如下。
pdLabelName和pdGroupLabelName:必须与vLLM PD部署中的Pod标签一致。prefillValue、decodeValue:必须与Pod的openfuyao.com/pdRole标签值匹配。- 确保vLLM PD部署的
groupID与路由策略中的分组标签匹配。
权重参数调整说明如下。
- Prefill相关权重:调整Prefill阶段的路由决策。
prefillWaitingRequestWeight:Prefill等待请求数的影响。prefillPodScoreWeight:Prefill Pod评分的影响。
- Decode相关权重:调整Decode阶段的路由决策。
decodeWaitingRequestWeight:Decode等待请求数的影响。decodePodScoreWeight:Decode Pod评分的影响。
- 通用权重:同时影响Prefill和Decode。
kvCacheHitNotRateWeight:KV Cache未命中率的影响。xpuCacheUsageWeight:XPU缓存使用率的影响。
KVCache Indexer配置与上述保持一致。
pd bucket
inferenceExtension:
pluginsConfigFile: "epp-pd-bucket.yaml"
pluginsCustomConfig:
epp-pd-bucket.yaml: |
apiVersion: inference.networking.x-k8s.io/v1alpha1
kind: EndpointPickerConfig
plugins:
- type: filter-by-pd-label # PD 标签过滤插件
- type: scorer-pd-bucket # PD Bucket 评分插件
- type: pd-header-handler # PD 请求头处理插件
schedulingProfiles:
- name: default
plugins:
- pluginRef: filter-by-pd-label
- pluginRef: scorer-pd-bucket
weight: 1
- pluginRef: pd-header-handlerpd bucket策略使用的插件如下。
filter-by-pd-label:根据PD角色(Prefill/Decode)和分组ID过滤推理服务实例。
scorer-pd-bucket:基于请求长度和Pod负载状态进行评分,将请求路由到负载最轻的Bucket。
pd-header-handler:处理PD分离架构所需的请求头信息。
其中filter-by-pd-label、scorer-pd-bucket两个插件的参数说明如表4、表6所示。
表6 scorer-pd-bucket参数说明
| 参数 | 类型 | 说明 | 缺省值 |
|---|---|---|---|
alpha | float | 负载评分系数。 | 1.0 |
beta | float | 请求长度评分系数。 | 2.0 |
decayFactor | float | 负载衰减因子(0-1)。 | 0.99 |
bucketSeperateLength | int | Bucket分离长度阈值。 | 200 |
PD标签配置说明如下。
pdLabelName和pdGroupLabelName:必须与vLLM PD部署中的Pod标签一致。prefillValue、decodeValue:必须与Pod的openfuyao.com/pdRole标签值匹配。- 确保vLLM PD部署的
groupID与路由策略中的分组标签匹配。
评分算法参数说明如下。
- alpha:控制Pod当前负载在评分中的权重,值越大,负载影响越大。
- beta:控制请求长度在评分中的权重,值越大,请求长度影响越大。
- decayFactor:负载衰减因子,用于平滑负载变化,值越接近1,衰减越慢。
- bucketSeperateLength:请求长度阈值,用于区分长请求和短请求,将请求路由到不同的Bucket。
评分权重说明如下。
weight: 1:评分插件在调度配置中的权重,可根据需要调整。
工作原理
- 请求分类:根据请求长度与
bucketSeperateLength比较,将请求分为长请求和短请求。 - 负载评分:结合Pod的当前负载和负载衰减因子计算负载评分。
- 综合评分:根据
alpha和beta权重,综合负载评分和请求长度评分。 - 路由选择:选择评分最低(负载最轻)的Pod进行路由。
其他路由策略
接下来将介绍其他常用的路由策略及其配置方法。
aggregate random
inferenceExtension:
pluginsConfigFile: "epp-aggregate-random.yaml"
pluginsCustomConfig:
epp-aggregate-kv-cache-aware.yaml: |
apiVersion: inference.networking.x-k8s.io/v1alpha1
kind: EndpointPickerConfig
plugins:
- type: picker-min-random # 仅使用随机选择器
schedulingProfiles:
- name: default
plugins:
- pluginRef: picker-min-randomaggregate random策略使用的插件为picker-min-random。
random pd
inferenceExtension:
pluginsConfigFile: "epp-random-pd.yaml"
pluginsCustomConfig:
epp-random-pd-bucket.yaml: |
apiVersion: inference.networking.x-k8s.io/v1alpha1
kind: EndpointPickerConfig
plugins:
- type: filter-by-pd-label # PD 标签过滤插件
- type: picker-random-pd-bucket # 随机 PD Bucket 选择器
- type: pd-header-handler # PD 请求头处理插件
schedulingProfiles:
- name: default
plugins:
- pluginRef: filter-by-pd-label
- pluginRef: picker-random-pd-bucket
- pluginRef: pd-header-handlerrandom pd策略使用的插件如下。
filter-by-pd-label:根据PD角色(Prefill/Decode)和分组ID过滤推理服务实例。
picker-random-pd:从符合条件的Pod中随机选择一个,实现基础的负载均衡。
pd-header-handler:处理PD分离架构所需的请求头信息。
配置容灾能力
前提条件
已在K8s环境部署GIE支持的开源网关。
背景信息
已支持的容灾能力包括自动切流、故障恢复以及请求重试,目的是在推理后端故障或重启时保证请求流量的无损或低损切换,以及推理请求因各种异常情况失败时,网关按照预定规则自动重试请求。容灾能力的架构如下图所示。
图2 容灾能力架构 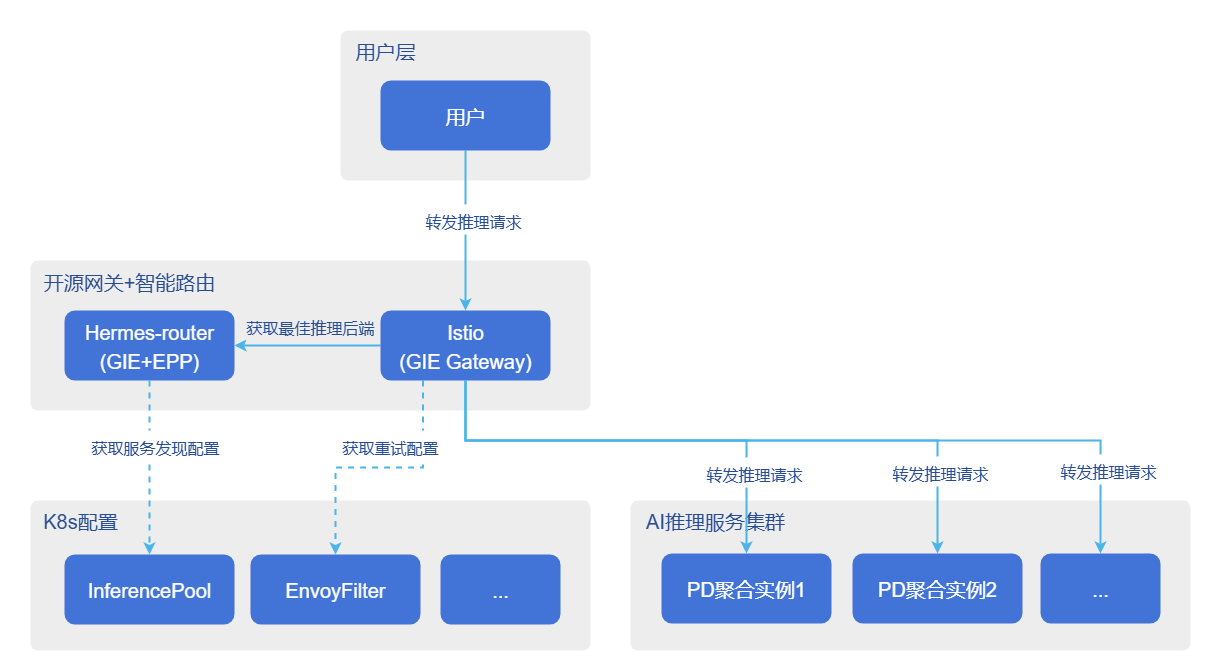
自动切流
自动切流流程如下。
- 故障判定:监控系统检测到后端服务业务异常(如服务长时间无响应)。
- 触发退出:触发故障处理服务的优雅退出流程。
- 主动下线:删除故障后端服务的Pod(或触发Pod自动终止)。
- 流量切换:
- 新流量:Pod删除后,K8s Endpoint Controller会将该IP地址从Service/InferencePool列表中移除,新流量自动路由到其他节点。
- 在途流量:对于正在发送给故障Pod的请求,由于Pod终止或网络不可达,请求会失败。此时网关代理捕获5xx错误或连接失败,触发自动重试,将请求转发给其他健康的后端服务。
故障恢复
故障恢复流程如下。
- 重启服务:由K8s集群或用户手动拉起新的推理后端Pod。
- 服务发现预热:EPP发现并等待Pod就绪,并通过发送推理请求验证服务可用性。
- 上线接流:验证通过后,EPP将新Pod加入可用服务后端列表。
请求重试
请求重试机制用于处理超时或异常的推理请求,确保系统的可靠性和容错能力。在GIE架构中,重试机制需要在网关数据平面进行配置。推理请求经过网关转发时,重试逻辑由网关的Envoy代理直接执行,具体的请求重试逻辑如下图所示。
图3 容灾能力请求重试流程 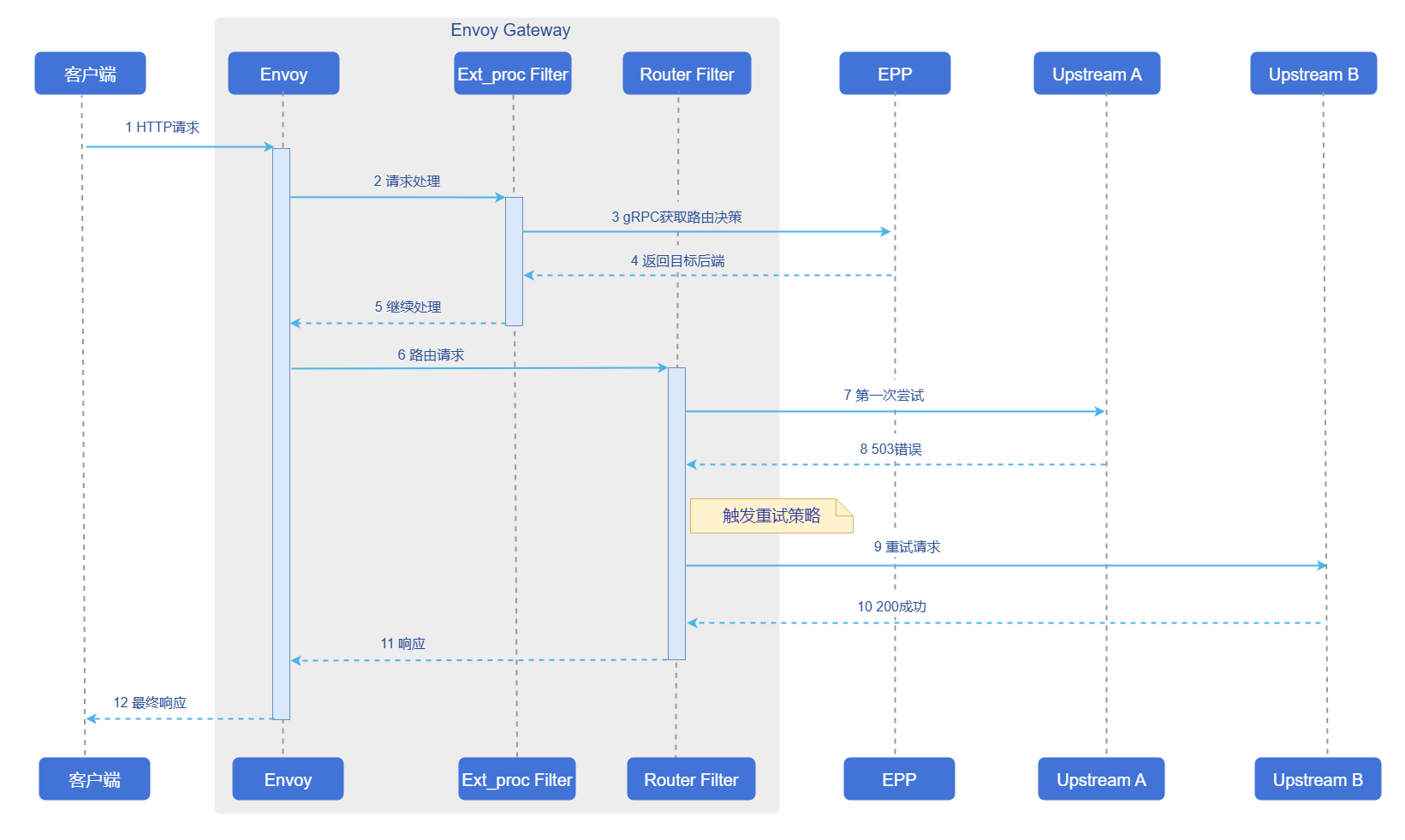
使用限制
- 当前容灾能力在开源网关Istio上完成验证,本小节中的配置适用于Istio。
- 由于Envoy数据平面的运行逻辑限制,触发网关重试请求时,网关不会再次调用EPP,而是从inferencepool资源池的推理后端Pod中进行选取。
- 因当前重试机制要求推理后端以Pod为资源粒度,所以不支持inferencepool资源池中包含Prefill、Decode等不提供完整推理能力的Pod资源的情况,其他容灾能力正常支持。当前重试机制暂不支持的路由策略包含:pd kv cache aware、pd bucket和random pd。
操作步骤
自动切流与故障恢复能力已作为Hermes-router的基础能力直接支持,用户仅需关注请求重试相关配置。
独立部署时开启容灾
独立部署Hermes-router时,推理服务所需的其他组件(开源网关、推理后端等)都由用户单独部署,用户需要在charts/hermes-router/values.yaml中增加如下配置以启用容灾。
provider:
istio:
destinationRule:
trafficPolicy:
tls:
mode: SIMPLE
insecureSkipVerify: true
retryConfig:
enabled: false
retryOn: "connect-failure,refused-stream,unavailable,cancelled,retriable-status-codes,5xx,reset"
numRetries: 3上述配置中的参数说明如下表所示。
表7 容灾能力请求重试参数
| 参数 | 说明 |
|---|---|
enabled | 是否开启请求重试能力,可选:true/false。 |
retryOn | 触发重试的错误类型列表,典型可选值包括:connect-failure、refused-stream、unavailable、cancelled、retriable-status-codes、5xx、reset等,可按需组合。 |
numRetries | 单次请求允许的最大重试次数。 |
mode | Istio与后端通信时的TLS模式,可选:DISABLE(不启用TLS)、SIMPLE(单向TLS)、MUTUAL/ISTIO_MUTUAL(双向TLS,依赖证书或Istio提供的身份)。 |
insecureSkipVerify | 是否跳过对后端服务证书的校验,可选:true/false;true仅建议在测试/验证环境使用,生产环境推荐设置为false。 |
独立部署Hermes-router时,建议为推理后端Pod配置健康探针以增强容灾效果。
通过InferNex部署时开启容灾
通过InferNex部署时,容灾配置已在helm chart中预置,用户只需在charts/infernex/values.yaml中将provider.istio.retryConfig.enabled设置为true即可启用请求重试能力。重试策略参数(如retryOn、numRetries)可根据业务需求调整,配置方式与独立部署时相同。
InferNex中的推理后端已默认配置了健康探针,无需额外配置。
遵循 木兰宽松许可证第2版(MulanPSL2)
