AI推理鹰眼
特性介绍
Eagle Eye是面向AI推理场景的可观测体系,旨在提供从业务运行态、系统运行态到硬件健康的全链路指标采集、实时传输与智能诊断。该体系融合了Prometheus的周期性指标采集与NATS的低延迟推送机制,既能支撑扩缩容决策的趋势分析,也能满足智能路由对秒级数据更新的需求。通过独立的硬件健康诊断模块,实现对NPU/GPU、温度、功耗、错误码等底层指标的持续监测与异常识别,构建“采集—传输—诊断—评估”的闭环监控能力,为AI推理系统的稳定性、性能优化与资源调度提供坚实的数据支撑。
应用场景
- 系统资源健康监控:实时监控系统运行态(如CPU、内存、网络使用情况等)和硬件资源(如GPU利用率、温度等),确保系统资源的健康与稳定,及时发现并解决资源瓶颈,确保系统高效运行。
- 推理过程性能优化:实时监控推理流程中的各个阶段(如prefill、decode等)的性能指标(如延迟、吞吐量)和资源使用情况,识别并分析性能瓶颈,优化模型执行效率,提升推理任务的响应速度和计算效率。
- 硬件故障诊断与修复:查看硬件诊断模块提供的异常分析报告,报告中包含故障模式识别与处置建议,帮助快速定位并解决硬件故障。系统能够实时监测NPU/GPU、温度、功耗等硬件状态,生成详细的故障分析报告,提供具体的故障原因和修复方案,确保硬件的稳定性和可靠性。
- 自动扩缩容决策:获取SLA相关指标(如吞吐率、延迟等),将这些数据作为自动扩缩容决策的依据,确保推理服务根据负载和性能需求动态扩展或缩减,达到弹性伸缩的目标。
- 智能路由决策:通过秒级实时数据更新,使智能路能基于最新的数据迅速做出决策,从而优化AI推理过程中的响应速度。
能力范围
- 多层指标覆盖:覆盖业务运行态(如请求队列长度、响应延迟)、系统运行态(CPU、内存、容器状态)及硬件健康指标(温度、功耗、错误码等),实现从业务到硬件的全链路观测。
- 近实时指标传输:面向对时效性要求高的模块(如智能路由),通过NATS实现秒级指标推送,确保推理过程中的关键性能指标(如等待执行的推理请求数、NPU/GPU KV Cache利用率等)能够被及时感知并影响决策。
- 扩缩容决策支撑:将采集到的系统与运行态指标同步上报至Prometheus,用于周期性计算与趋势评估。
- 硬件健康检查与诊断:构建独立的硬件健康诊断模块,周期性采集NPU/GPU温度、功耗、错误码等底层指标,并通过NATS实时上报。诊断模块订阅并分析采集数据,结合设备型号、驱动与固件信息,基于阈值规则与异常指标分析,识别典型故障模式并输出诊断结论与处置建议,实现从数据采集到健康评估的闭环。
实现原理
逻辑视图
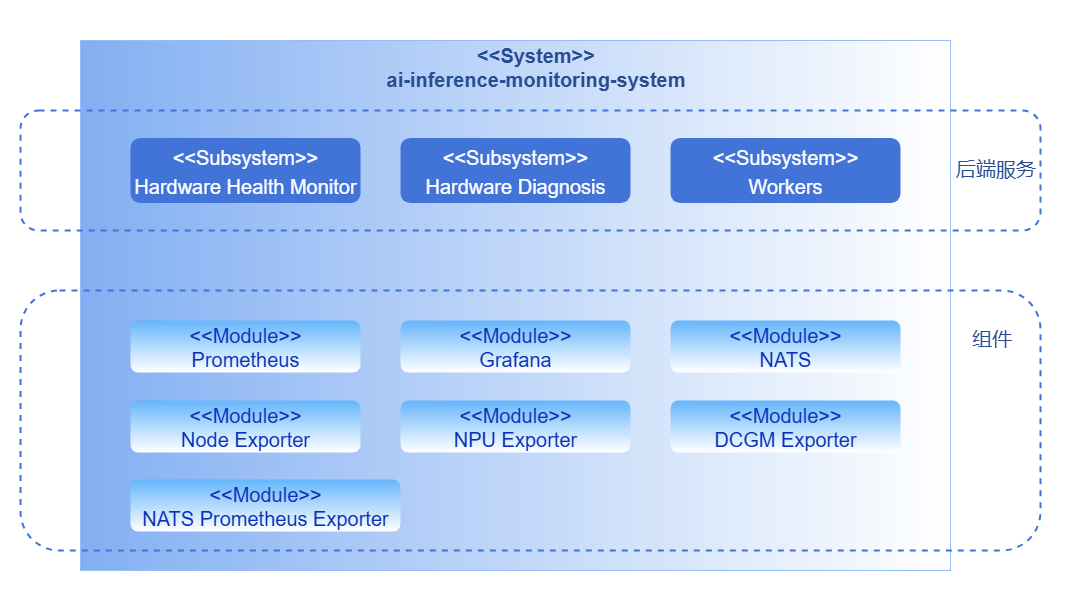
监控系统按照业务层次分为后端层和组件层。
后端层
- Hardware Health Monitor: 硬件健康检测模块作为独立运行的采集组件,以周期性任务方式主动执行指标采集与上报。模块在运行过程中会按照固定采集周期调用底层接口(DCMI、NVML)或解析系统日志(dmesg),获取设备运行状态与健康信息。采集结果通过NATS实时发布至诊断模块,实现采集与诊断的解耦。
- Hardware Diagnosis: 诊断模块订阅采集模块通过NATS发布的指标数据,结合设备型号、驱动及固件信息,对硬件健康状态进行实时分析。模块支持阈值判断与异常,识别典型故障模式并输出诊断结论与处置建议,实现从数据采集到健康评估的闭环。
组件层
组件层提供底层的指标采集,传输与展示能力,涵盖了以下关键模块:指标采集(Exporter)、高性能分布式消息系统(NATS)、指标存储(Prometheus)以及展示(Grafana)。
数据流图
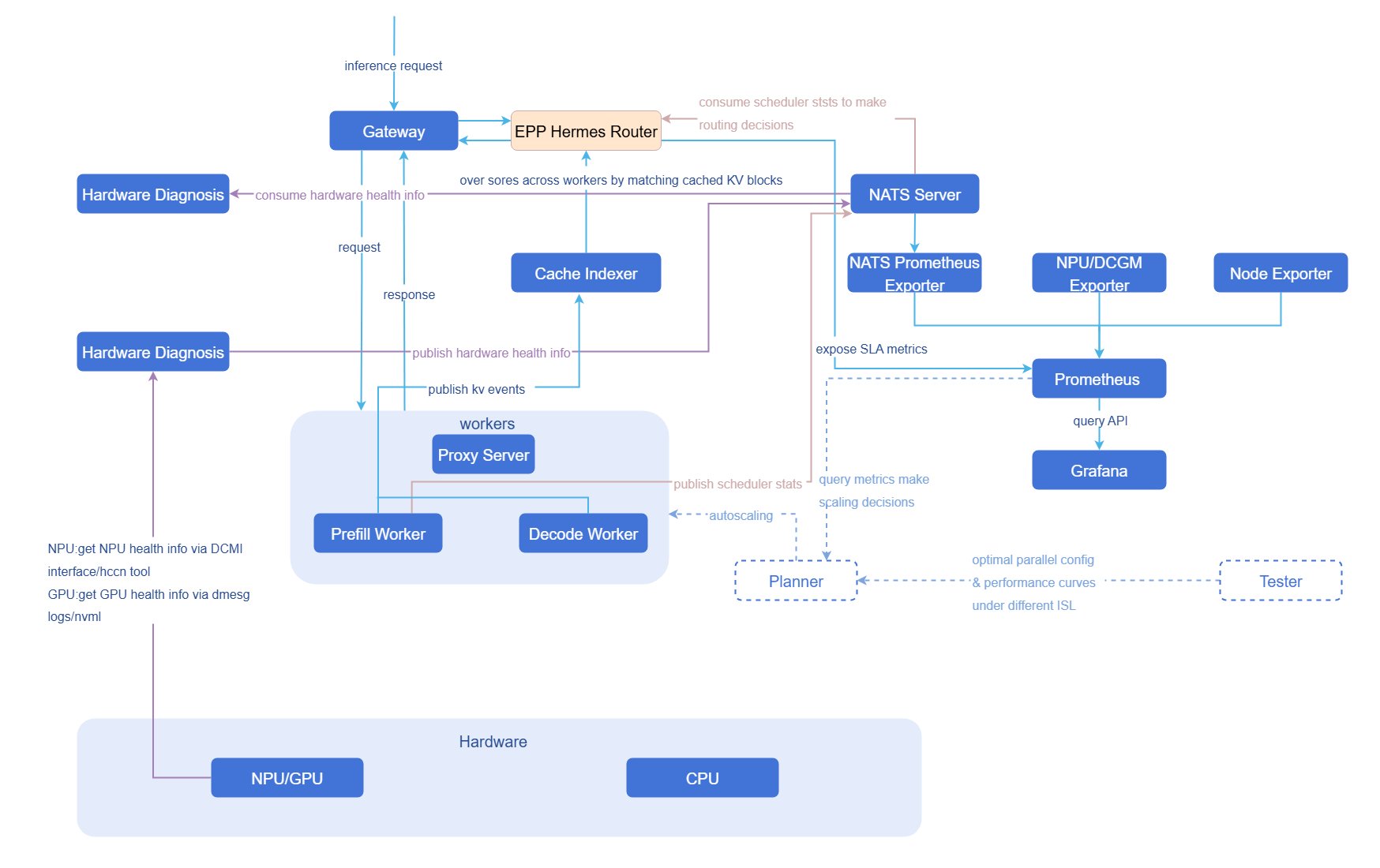
与相关特性的关系
依赖推理引擎(如vLLM)。
安装
前提条件
硬件要求
Eagle Eye本身对硬件环境无特殊要求。
软件要求
Kubernetes v1.33.0及以上版本。
开始安装
openFuyao平台
- 登录openFuyao管理面。
- 左侧导航栏选择“应用市场 > 应用列表”跳转到“应用列表”界面。
- 勾选左侧“场景”中的“人工智能/机器学习”,查找“eagle-eye”卡片。或通过搜索框输入“eagle-eye”。
- 单击“部署”进入“部署”界面。
- 输入应用名称、选择安装版本和命名空间。命名空间可以选用已有命名空间或新建命名空间,创建命名空间请参见命名空间。
- 在参数配置的“values.yaml”中对路由进行配置。
- 单击“部署”完成安装。
独立部署
除了openFuyao平台安装部署,本特性还提供独立部署功能,有以下两种途径:
- 从openFuyao官方镜像仓库获取项目安装包。
执行如下命令,拉取项目安装包。
helm pull oci://cr.openfuyao.cn/charts/eagle-eye --version xxx其中
xxx需替换为具体项目安装包版本,如0.0.0-latest。拉取得到的安装包为压缩包形式。执行如下命令,解压安装包。
cdtar -zxvf eagle-eye安装部署。
执行如下命令,在eagle-eye同级目录下。
helm install eagle-eye -n xxxxxx .
- 从openFuyao GitCode仓库获取。
执行如下命令,从仓库拉取项目。
git clone https://gitcode.com/openFuyao/eagle-eye.git安装部署。 执行如下命令,在eagle-eye同级目录下。
helm install eagle-eye -n xxxxxx .
面向智能路由的高实时性指标采集与上报
为满足智能路由等模块的高时效性要求,系统采用NATS进行关键性能指标的秒级推送。这使得等待请求数、NPU/GPU KVCache利用率等指标能被实时感知,从而动态调整决策。
目前只支持vLLM部署。
前置条件
- Kubernetes集群已部署并可正常访问
- 已安装
kubectl命令行工具并配置好集群访问权限 - 节点上已安装Ascend驱动和相关依赖
- NATS已部署并正常运行
部署步骤
选用NATS发布/订阅模型作为指标传输方式。CustomStatLogger是在vLLM中通过继承StatLoggerBase抽象类实现的自定义统计数据记录器。作为发布者,CustomStatLogger会在每次解码批次结束后,主动生成结构化的运行指标消息,并将其发布到指定的NATS主题;Router作为订阅者,只需在该主题上注册侦听,即可在消息发布的瞬间接收并触发后续处理逻辑。
为避免首批消息丢失,订阅端(Router)需先于发布端(CustomStatLogger)完成连接与订阅。
Router (订阅端)。
Router作为订阅者,主要负责接收发布的运行指标消息并触发相应的处理逻辑。参考以下代码示例来实现Router,并将其部署到Kubernetes集群中。import logging import json from nats.aio.client import Client as NATS_Client logger = logging.getLogger() class RouterSubscriber: def __init__(self, server_address: str, topic: str): """ 初始化RouterSubscriber实例 :param server_address: NATS服务器地址 :param topic: 订阅的主题 """ self.server_address = server_address self.topic = topic self.client = NATS_Client() async def connect(self): """ 建立与NATS服务器的连接 """ try: # 建立NATS长连接 await self.client.connect(self.server_address) logger.info("Connected to NATS server at %s", self.server_address) except Exception as e: logger.error("Failed to connect to NATS server: %s", e) raise e async def subscribe(self, topic: str, message_handler): """ 订阅指定主题,并将接收到的消息交给业务逻辑处理 :param message_handler: 业务逻辑处理函数,用于处理接收到的消息 """ try: async def on_message(msg): """ 消息回调函数,处理订阅到的消息 :param msg: NATS消息 """ logger.info("Received message on topic %s", topic) await message_handler(msg) # 确保NATS连接 if not self.client.is_connected: await self.connect() # 注册订阅主题,并绑定消息回调函数 await self.client.subscribe(topic, cb=on_message) logger.info("Successfully subscribed to NATS topic %s", topic) except Exception as e: logger.error("Failed to subscribe to NATS topic %s: %s", topic, e) raise e async def message_handler(self, msg) -> None: """ NATS原始回调,负责: 1. 从msg中解码数据; 2. 调用parse_message做JSON反序列化; 3. 将解析后的结构化数据交给后续业务逻辑处理。 """ try: data = msg.data.decode("utf-8") except Exception as exc: logger.error("Failed to decode NATS message: %s", exc) return data_dict = self.parse_message(data) if not data_dict: # 解析失败直接返回,避免后续逻辑异常 return # TODO: 在这里处理具体业务逻辑,例如根据指标做路由决策 ... def parse_message(self, data: str) -> Dict[str, Any]: """ 将NATS消息体从JSON字符串反序列化为字典。 解析失败时记录日志并返回空字典。 """ try: return json.loads(data) except Exception as exc: logger.error("Failed to parse message: %s, raw: %r", exc, data) return {}Customstatlogger (发布端)。
CustomStatLogger是发布者,它负责生成并发布实时的运行指标数据。每次解码批次结束后,CustomStatLogger将结构化的指标消息发布到指定的NATS主题(该主题应与订阅方的主题匹配,当前主题eagle_eye.routing_metrics),供Router订阅。2.1 打包源代码。
在项目根目录下执行以下命令,将源代码打包为压缩文件。
bashtar -czf source_code.tar.gz src/ requirements.txt2.2 创建ConfigMap。
将压缩包作为二进制文件导入到ConfigMap中。
bash# 检查是否存在namespace,如果不存在则创建它 kubectl get namespace ai-inference || kubectl create namespace ai-inference # 如果已存在同名ConfigMap,先删除 kubectl delete configmap vllm-source-code -n ai-inference --ignore-not-found # 创建新的ConfigMap kubectl create configmap vllm-source-code \ --from-file=source_code.tar.gz=source_code.tar.gz \ -n ai-inference2.3 部署服务。
应用部署YAML文件。
bashkubectl apply -f ./docs/routing-metrics/vllm_eagle_eye.yaml2.4 检查部署状态。
bash# 查看Pod运行状态 kubectl get pods -n ai-inference -l app=vllm-eagle-eye # 查看Pod详细信息 kubectl describe pod -n ai-inference -l app=vllm-eagle-eye # 查看Pod日志 kubectl logs -n ai-inference -l app=vllm-eagle-eye -f验证步骤。
3.1 方式一:使用临时Pod验证。
3.1.1 获取服务Pod IP。
bashkubectl get pod -n ai-inference -l app=vllm-eagle-eye -o wide记录输出中的
IP地址(例如:10.244.1.5)。3.1.2 启动临时测试Pod。
bashkubectl run curl-test --image=curlimages/curl -n ai-inference -it --rm --restart=Never -- sh3.1.3 在临时Pod中发送测试请求。
在临时Pod的shell中执行(将
<POD_IP>替换为实际IP):bashcurl -X POST http://<POD_IP>:8000/generate \ -H "Content-Type: application/json" \ -d '{"prompt": "Hello AI"}'3.2 方式二:使用port-forward验证。
bash# 端口转发 kubectl port-forward -n ai-inference deployment/vllm-eagle-eye 8000:8000 # 在另一个终端发送请求 curl -X POST http://localhost:8000/generate \ -H "Content-Type: application/json" \ -d '{"prompt": "Hello AI"}'清理资源。
bash# 删除Deployment kubectl delete -f ./docs/routing-metrics/vllm_eagle_eye.yaml # 删除ConfigMap kubectl delete configmap vllm-source-code -n ai-inference # 删除临时Pod kubectl delete pod -n ai-inference curl-test
常见问题
Pod启动失败。
bash# 查看Pod事件 kubectl describe pod -n ai-inference -l app=vllm-eagle-eye # 查看init容器日志 kubectl logs -n ai-inference <pod-name> -c code-extractor依赖安装失败。
如果集群无法联网,需要提前将依赖包打入压缩包。
bash# 下载依赖到本地 pip download -r requirements.txt -d packages/ # 打包时包含依赖 tar -czf source_code.tar.gz src/ requirements.txt packages/
遵循 木兰宽松许可证第2版(MulanPSL2)
