AI推理集成部署
特性介绍
AI推理集成部署(InferNex)是一个专为云原生环境下AI推理服务优化所设计的端到端集成部署方案。该方案基于Kubernetes官方项目Gateway API Inference Extension (GIE) 和主流LLM技术栈构建,通过Helm Chart将智能路由、高性能推理后端、全局KVCache管理及推理可观测体系等核心加速模块无缝集成。它提供从请求接入、动态路由、推理执行到资源管理与监控的完整加速链路,旨在提升推理吞吐量并降低时延,实现一站式的高效AI服务部署体验。
应用场景
- 传统聚合推理架构部署:支持基于vLLM的聚合推理模式,适用于中小规模推理场景。
- Prefill-Decode分离推理架构部署:支持Prefill和Decode阶段分离的xPyD高性能推理架构,适用于大规模推理场景。
能力范围
- 基于KV Aware感知、GPU缓存使用率、请求等待队列长度等多个维度的负载均衡算法,实现端到端的推理请求调度。
- 支持兼容Gateway API和Gateway API Inference Extension标准的开源网关(如Istio等),集成流量管理、服务发现、安全认证、可观测性、限流熔断等核心能力。
- 支持用户配置智能路由的路由策略,实现KV-Aware,分桶调度等高级路由功能。
- 支持聚合模式和xPyD分离模式推理引擎。
- 支持用户配置推理引擎PD分离模式与xPyD的推理引擎节点数量。
- 拥有分布式KVCache元数据管理,提供全局推理节点的KVCache感知能力。
- 适配华为昇腾910B4芯片的推理加速。
- 支持用户配置推理芯片。
- 实现从推理请求到底层硬件的全链路指标可观测,覆盖业务运行态、系统运行态与硬件健康态的多层指标采集与观测能力。
- 业务运行态:请求队列长度、请求延迟、吞吐率等。
- 系统运行态:CPU、内存、容器运行状态等。
- 硬件健康态:NPU/GPU 温度、功耗、错误码等。
- 提供独立的硬件健康诊断模块,周期性采集NPU/GPU温度、功耗、错误码等底层指标,并通过NATS实时上报。诊断模块订阅并分析采集数据,结合设备型号、驱动与固件信息,基于阈值规则与异常指标分析,识别典型故障模式并输出诊断结论与处置建议,实现从数据采集到健康评估的闭环。
- 提供SLA相关指标(如吞吐率、延迟等),用于支撑推理服务的自动扩缩容决策,实现基于负载与性能的弹性伸缩。
- 支持以Helm形式在K8s环境一键部署推理集群。
亮点特征
- 开源网关能力集成: 兼容主流开源网关(如Istio等),集成流量管理、服务发现、安全认证等核心能力。
- KV-Aware路由策略:相比传统负载均衡,通过感知全局推理节点的KVCache状态实现更智能的请求路由,减少不必要的重复KVCache计算。
- Prefill-Decode分离架构:支持业界先进的PD分离架构,大幅提升大模型推理吞吐量。
- PD-Bucket路由策略:PD分离架构下的分桶调度策略,在长短请求、中高并发场景提升推理吞吐量。
- vLLM Mooncake集成:vLLM v1架构集成Mooncake分布式KVCache管理系统,实现跨实例的KVCache高速传输。
- 秒级指标推送:集成NATS分布式消息队列系统,实现高效的秒级指标推送。采集模块在获取硬件健康数据后,立即通过NATS将数据推送至诊断模块。该机制确保诊断模块能够快速接收到最新状态信息,进行及时的异常检测和故障分析。
- 一键部署:通过Helm Chart实现三大组件在K8s环境一键式集成部署。
实现原理
PD聚合模式
图1 PD聚合模式AI推理集成部署图
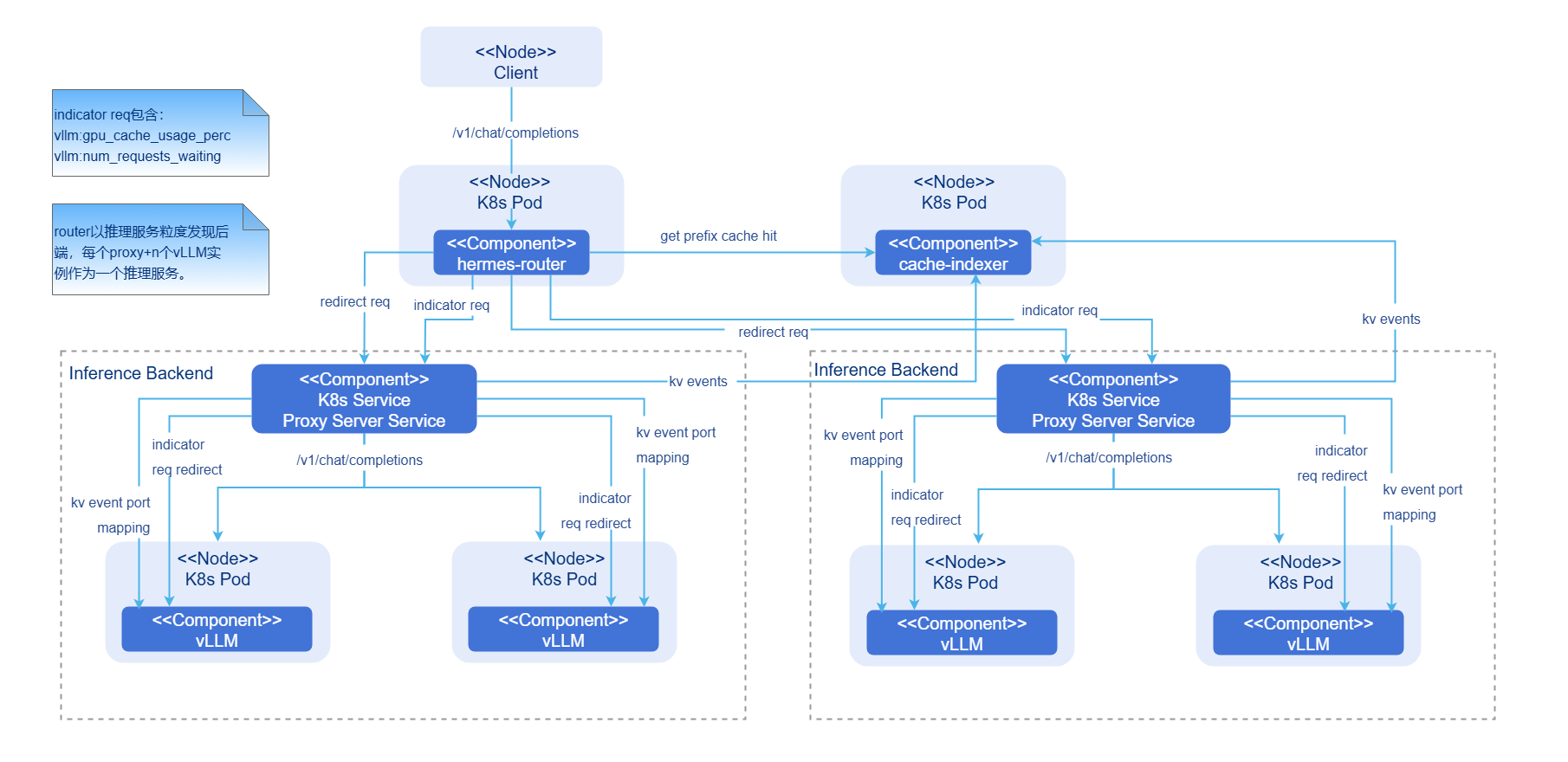
- hermes-router:智能路由模块。负责接收用户请求并根据路由策略转发到最优的推理后端服务。
- cache-indexer:KVCache全局管理器,为路由决策提供数据支持。
- Inference Backend:推理后端模块,基于vLLM提供高性能大模型推理服务,由1个Proxy Server Service和n个vLLM推理引擎实例组成。
- Proxy Server Service:推理后端服务的流量入口。
- vLLM:vLLM推理引擎实例。
组件初始化流程:
智能路由:
- 智能路由读取配置。
- 启动推理后端服务发现模块(周期性更新后端列表)。
- 启动推理后端指标收集模块(周期性更新后端负载指标)。
推理后端:
- 根据配置启动vLLM推理引擎实例。
- vLLM推理引擎实例绑定硬件设备,加载模型。
全局KVCache管理器:
- 根据配置启动cache-indexer实例。
- 启动推理引擎实例自动发现模块(周期性更新推理实例列表)。
请求流程:
- 请求接入:用户请求首先到达hermes-router。
- KVCache查询:hermes-router向cache-indexer查询该请求在集群中的前缀命中信息。
- 路由决策:基于KVCache命中情况、GPU利用率等指标选择最优推理后端服务。
- 请求转发:将请求转发到选定的推理后端服务。
- 推理执行:vLLM推理引擎执行计算。
- 结果返回:vLLM推理引擎生成请求结果后返回hermes-router,随后返回客户端。
- 全局KVCache管理异步更新:Prefill推理引擎在预填充过程中生产KV Event,cache-indexer订阅该KV Event并实时更新全局KVCache元数据。
PD分离模式
图2 PD分离模式AI推理集成部署图
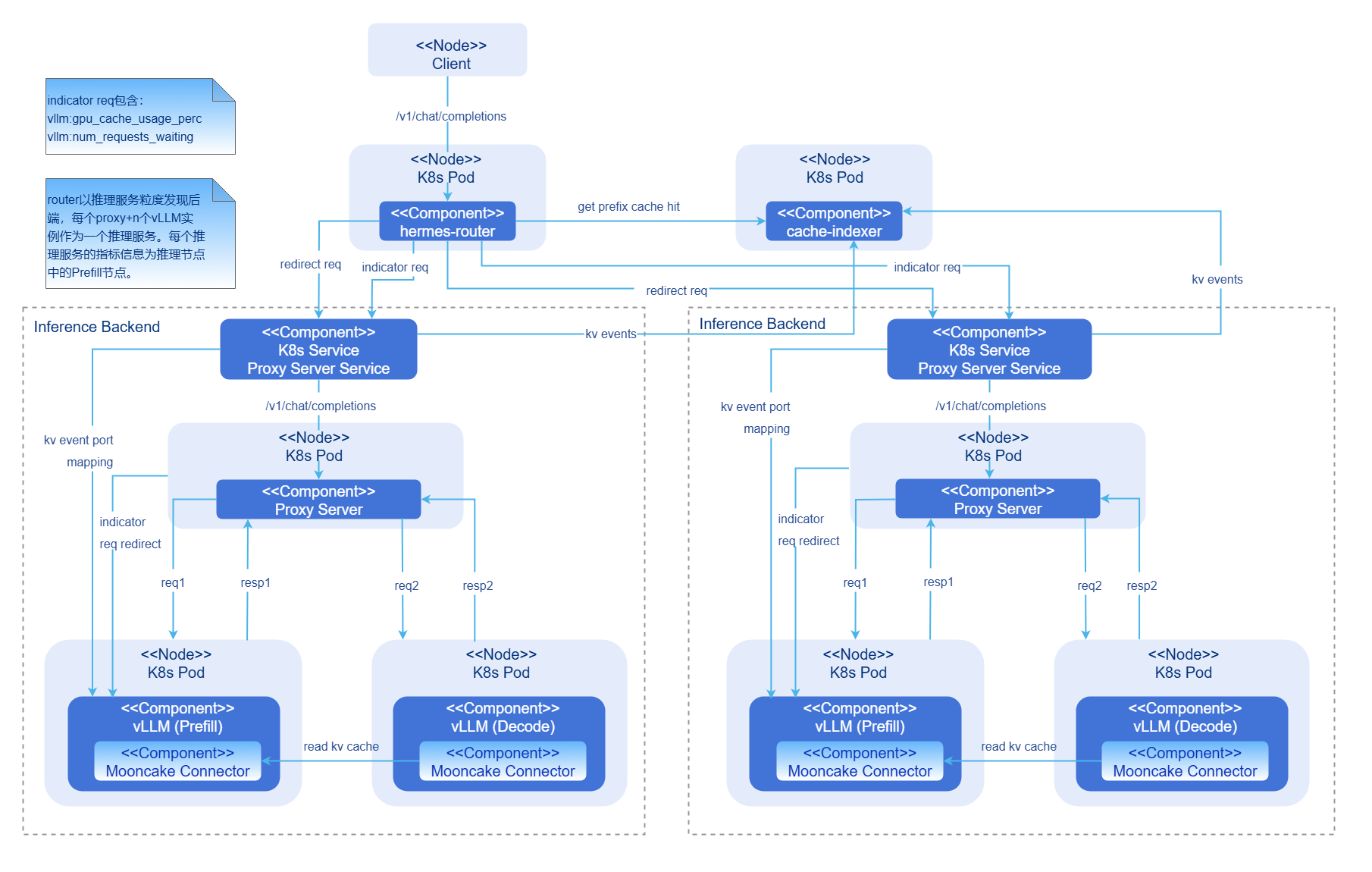
- hermes-router:智能路由模块。负责接收用户请求并根据路由策略转发到最优的推理后端服务。
- cache-indexer:KVCache全局管理器,为路由决策提供数据支持。
- Inference Backend:推理后端模块,基于vLLM提供高性能大模型推理服务,由1个Proxy Server Service,1个Proxy Server实例,n个vLLM Prefill推理引擎实例和n个vLLM Decode推理引擎实例组成。
- Proxy Server Service:推理后端服务的流量入口。
- Proxy Server:二层路由转发组件。负责每个推理后端服务内的负载均衡路由。
- vLLM:vLLM推理引擎实例。
- Mooncake Connector: 负责PD实例之间的KVCache P2P高速传输。
组件初始化流程:
智能路由:
- 智能路由读取配置。
- 启动推理后端服务发现模块(周期性更新后端列表)。
- 启动推理后端指标收集模块(周期性更新后端负载指标)。
推理后端:
- 根据配置启动vLLM推理引擎实例。
- vLLM推理引擎实例绑定硬件设备,加载模型。
- Prefill推理引擎实例与Decode推理引擎实例与对方所暴露的KV connector端口建立连接。
- Proxy Server组件启动,开始对推理引擎实例自动发现(周期性更新推理引擎实例列表)。
全局KVCache管理器:
- 根据配置启动cache-indexer实例。
- 启动推理引擎实例自动发现模块(周期性更新推理实例列表)。
请求流程:
- 请求接入:用户请求首先到达开源网关与hermes-router。
- KVCache查询:Router向cache-indexer查询该请求在集群中的前缀命中信息。
- 路由决策:基于KVCache命中情况、GPU利用率等指标选择最优推理后端服务。
- 请求转发:将请求转发到选定的推理后端服务。
- 二层路由:在推理后端服务内Proxy Server提取hermes-router的路由决策结果,得到最优的PrefillPod和DecodePod,同时将请求二次转发到负载最小的Prefill推理引擎。
- 预填充阶段执行:Prefill推理引擎执行计算并将结果返回Proxy Server。Prefill推理引擎更新KVCache状态并发出KV Event。
- 解码阶段执行:Proxy Server二次转发请求到最优的Decode推理引擎。Decode推理引擎与先前的Prefill推理引擎建立连接并开始解码。
- 结果返回:Decode推理引擎生成请求结果后返回Proxy Server,随后通过Router返回客户端。
- 全局KVCache管理异步更新:Prefill推理引擎在预填充过程中生产的KV Event,cache-indexer订阅该KV Event并实时更新全局KVCache元数据。
AI推理可观测
实现原理请参见《AI推理鹰眼》。
与相关特性的关系
- 智能路由hermes-router组件依赖推理引擎(如vLLM)提供推理服务及指标接口。
- KVCache全局管理器cache-indexer组件依赖推理引擎(如vLLM)提供KVCache存储、移除事件。
相关实例
示例参考:values.yaml
安装
前提条件
硬件要求
- 每个推理节点至少一张推理芯片。
- 每个推理节点至少16GB内存,4CPU核。
软件要求
- Kubernetes v1.33.0及以上版本。
网络要求
- 能够访问镜像仓库:oci://cr.openfuyao.cn。
权限要求
- 用户具备创建RBAC资源的权限。
开始安装
独立部署
本特性有以下两种途径独立部署:
- 从openFuyao官方镜像仓库获取项目安装包。
拉取项目安装包。
bashhelm pull oci://cr.openfuyao.cn/charts/infernex --version xxx其中
xxx需替换为具体项目安装包版本,如0.20.0。拉取得到的安装包为压缩包形式。解压安装包。
bashtar -xzvf infernex-xxx.tgz其中
xxx需替换为具体项目安装包版本,如0.20.0。安装部署。
以release名称
infernex为例,执行安装前请确保:- 集群已创建命名空间
istio-system(Istio Gateway资源必须部署在此命名空间)。 - 集群已创建
values.yaml中global.namespace配置项指定的命名空间。其他组件(如inference-backend、hermes-router、cache-indexer等)的命名空间可通过values.yaml中的global.namespace配置项进行设置,默认值为ai-inference。
在
infernex同级目录下执行如下命令:bashhelm install -n istio-system infernex ./infernex- 集群已创建命名空间
- 从openFuyao GitCode仓库获取:
从仓库拉取项目。
bashgit clone https://gitcode.com/openFuyao/InferNex.git安装部署。
以release名称
infernex为例, helm安装时由于集成开源网关istio,需要指定命名空间istio-system,其他组件的命名空间设定可在values.yaml中的global.namespace进行配置。在InferNex同级目录下执行如下命令:bashcd InferNex/charts/infernex helm dependency build helm install -n istio-system infernex .
配置AI推理集成部署
前提条件
- 已获取InferNex项目文件。
- InferNex会一键部署Istio网关,需要确保环境没有冲突。
- InferNex包含的组件在目标命名空间尚未安装部署:hermes-router、Inference Backend、cache-indexer、eagle-eye。
操作步骤
准备
values.yaml配置文件。用户参考开始安装章节找到
values.yaml配置文件。配置全局配置
- global.name:Inferencepool资源的名称,必须与
hermes-router.httpRoute.backend.name保持一致, 如果global.name为vllm-qwen-qwen3-8b,则hermes-router.httpRoute.backend.name也必须为vllm-qwen-qwen3-8b。 - global.namespace: 指定所有应用组件(包括inference-backend、hermes-router、cache-indexer等)部署的目标Kubernetes命名空间,默认值为
ai-inference。 - global.image: 定义所有
inference-backend服务实例的默认容器镜像配置。 - global.env: 定义所有
inference-backend服务实例的默认环境变量,这些环境变量会被注入到所有vLLM容器中。 - global.cachePath: 指定主机上存储
HuggingFace模型缓存的路径,该路径会通过hostPath方式挂载到所有inference-backend容器的/root/.cache目录。
- global.name:Inferencepool资源的名称,必须与
配置智能路由参数。
配置网关参数
- inferenceGateway.name:Gateway资源的名称,必须与
hermes-router.httpRoute.parentRef.name保持一致。 - inferenceGateway.className:Gateway类名称,使用
"istio"表示由Istio控制平面管理。 - inferenceGateway.annotations:
networking.istio.io/service-type: "NodePort":指定Istio Gateway的Service类型为NodePort,允许通过节点IP和端口访问。若删除该项配置使用默认配置,网关会使用LoadBalancer的Service Type对外暴露服务。
- inferenceGateway.listeners:定义监听器配置。
name: http:监听器名称。port: 80:监听端口。protocol: HTTP:协议类型。
配置路由镜像拉取
- hermes-router.inferenceExtension.image.name:智能路由镜像地址。
- hermes-router.inferenceExtension.image.hub:智能路由镜像标签。
- hermes-router.image.tag:智能路由镜像拉取策略。
- hermes-router.image.pullPolicy:智能路由镜像拉取策略。
配置路由策略
- hermes-router.inferenceExtension.pluginsConfigFile: 指定要使用的路由策略配置文件名称,该名称必须与
hermes-router.inferenceExtension.pluginsCustomConfig中的键名一致。 - hermes-router.inferenceExtension.pluginsCustomConfig: 定义自定义的路由策略配置内容。目前支持以下路由策略:随机PD Bucket路由、PD Bucket分桶调度路由、PD KV Aware路由、聚合架构KV Aware路由。配置时必须包含路由策略中的插件配置和调度配置,具体配置示例可参考:hermes-router路由策略参考配置,该链接提供了上述所有路由策略的完整参考配置。
配置InferencePool
- hermes-router.inferencePool.modelServers.matchLabels: 推理服务标签选择器,用于选择加入InferencePool的 Pod,Pod必须同时满足所有标签,且仅在同一命名空间内匹配,不支持跨命名空间。
- hermes-router.inferencePool.targetPorts: InferencePool里各个推理服务实际监听的端口号,用于处理推理流量。
配置HTTPRoute
- hermes-router.httpRoute.parentRef.name: 指定
Gateway的名字,只有当请求通过该Gateway,请求才会被该HTTPRoute的路由规则匹配。 - hermes-router.httpRoute.backend.name: 指定
InferencePool的名字,Gateway会将匹配的请求转发到指定的InferencePool,需要和global.name保持一致。 - hermes-router.httpRoute.pathPrefix:
HTTPRoute的路径前缀匹配规则,只有请求路径符合该前缀的请求才会被路由到后端推理服务。例如:配置为/v1时,只有路径以/v1开头的请求(如/v1/chat/completions)才会被匹配并路由。
- inferenceGateway.name:Gateway资源的名称,必须与
配置推理后端参数。
- inference-backend.services: 推理服务配置,支持用户配置多个独立的vLLM推理服务。每个服务可独立配置模型、部署模式(聚合模式或PD分离模式)、资源等参数,实现多模型、多架构的混合部署。
基础配置
- name: 服务名称,用于生成Deployment、Service等资源名称。
- enabled: 是否启用该服务实例。
- mode: 推理后端服务形态,共有
aggreagted和pd两种可选,分别表示聚合架构和PD分离架构。 - service.type: Service类型,默认为ClusterIP。
- service.port: Service服务端口。
- model.name: 推理引擎使用的模型地址。
- openfuyao.model: 模型标识,会转换为标签openfuyao.com/model,用于InferencePool标签匹配, 需要和
hermes-router.inferencePool.modelServers.matchLabels保持一致。 - openfuyao.engine: 引擎类型,会转换为标签openfuyao.com/vllm,用于智能路由策略发现和过滤服务。
- openfuyao.pdRole: PD模式角色:aggregated,prefill或者decode,用于智能路由策略发现和过滤服务。
- openfuyao.pdGroupID: PD模式分组ID,在PD分离架构下需要设置,表示该推理服务下的所有Proxy Server服务,Prefill和Decode推理后端服务均在该分组内,用于智能路由策略发现和过滤服务。
配置PD分离模式下推理引擎
- pd.kvTransferConfig: 推理引擎的kv-transfer-config配置,具体配置可以参考vllm-ascend。
- pd.prefill.replicaAmount: Prefill引擎副本数。
- pd.prefill.tensorParallelSize: Prefill引擎张量并行度。
- pd.prefill.dataParallelSize: Prefill引擎数据并行度。
- pd.prefill.enablePrefixCaching: Prefill引擎是否启用前缀缓存。
- pd.prefill.maxModelLen: Prefill引擎最大模型长度。
- pd.prefill.maxNumBatchedTokens: Prefill引擎最大批处理token数。
- pd.prefill.gpuMemoryUtilization: Prefill引擎GPU显存利用率。
- pd.prefill.connectorBasePort:Prefill推理引擎实例的KVCache Connector通信端口。
- pd.decode.replicaAmount: Decode引擎副本数。
- pd.decode.tensorParallelSize: Decode引擎张量并行度。
- pd.decode.dataParallelSize: Decode引擎数据并行度。
- pd.decode.enablePrefixCaching: Decode引擎是否启用前缀缓存。
- pd.decode.maxModelLen: Decode引擎最大模型长度。
- pd.decode.maxNumBatchedTokens: Decode引擎最大批处理token数。
- pd.decode.gpuMemoryUtilization: Decode引擎GPU显存利用率。
- pd.decode.connectorBasePort:Decode推理引擎实例的KVCache Connector通信端口。
- pd.proxyServer.port: Proxy Server端口。
- pd.proxyServer.discoveryInterval: Proxy Server对推理后端服务发现间隔。
配置聚合模式下推理引擎
- aggregated.replicas: 聚合模式推理引擎副本数。
- aggregated.tensorParallelSize: 聚合模式推理引擎张量并行度。
- aggregated.dataParallelSize: 聚合模式推理引擎数据并行度。
- aggregated.enablePrefixCaching: 聚合模式推理引擎是否启用前缀缓存。
- aggregated.maxModelLen: 聚合模式推理引擎最大模型长度。
- aggregated.maxNumBatchedTokens: 聚合模式推理引擎最大批处理token数。
- aggregated.gpuMemoryUtilization: 聚合模式推理引擎GPU显存利用率。
配置推理引擎资源
- resources.requests.cpu: 聚合模式推理引擎CPU请求资源。
- resources.requests.memory: 聚合模式推理引擎内存请求资源。
- resources.limits.cpu: 聚合模式推理引擎CPU限制资源。
- resources.limits.memory: 聚合模式推理引擎内存限制资源。
配置推理引擎容器环境变量
- 环境变量配置适用于推理服务容器,用户可根据实际需求参考vllm-ascend环境变量配置说明文档自行配置。
配置KVCache全局管理器参数。
配置KVCache全局管理器的推理后端服务发现
cache-indexer.app.serviceDiscovery.labelSelector:对推理后端的自动服务发现的K8s Service资源标签。该标签在
inference-backend.service.openfuyao配置。示例:若推理后端K8s Service资源标签配置为:yamllabels: openfuyao.com/engine: vllm inference-backend: "true"则该属性配置为
labelSelector: "inference-backend=true,openfuyao.com/engine=vllm"。cache-indexer.app.serviceDiscovery.refreshInterval:对推理后端的自动服务发现时间间隔(单位:秒)。
配置KVCache全局管理器的K8s服务
- cache-indexer.service.name:cache-indexer的K8s Service名称。
- cache-indexer.service.port:cache-indexer的K8s Service端口。
配置KVCache全局管理器镜像拉取
- cache-indexer.image.repository:cache-indexer镜像地址。
- cache-indexer.image.tag:cache-indexer镜像标签。
- cache-indexer.image.pullPolicy:cache-indexer镜像拉取策略。
配置AI推理可观测参数。
配置是否开启硬件健康检测和诊断
- hardware-monitor-diagnosis.enabled:控制是否启用硬件健康检测和诊断功能。
配置硬件健康检测镜像拉取
- hardware-monitor.images.core.repository:hardware-monitor镜像地址。
- hardware-monitor.images.core.tag:hardware-monitor镜像标签。
- hardware-monitor.images.core.pullPolicy:hardware-monitor镜像拉取策略。
配置硬件诊断镜像拉取
- hardware-diagnosis.images.core.repository:hardware-diagnosis镜像地址。
- hardware-diagnosis.images.core.tag:hardware-diagnosis镜像标签。
- hardware-diagnosis.images.core.pullPolicy:hardware-diagnosis镜像拉取策略。
配置是否开启prometheus监控K8s集群的套件
- kube-prometheus-stack.enabled:控制是否启用Prometheus监控K8s集群的功能。
应用配置
用户参考安装章节部署以应用配置。
使用AI推理
前提条件
硬件要求
- 每个推理节点至少一张推理芯片。
- 每个推理节点至少16GB内存,4 CPU核。
- 在PD分离场景Mooncake传输KVCache时,若使用HCCL协议,需要确保
hccn.conf已配置设备ip、掩码信息。
软件要求
- Kubernetes v1.33.0及以上版本。
- 已经安装InferNex包含的必要组件:hermes-router、inference-backend、cache-indexer。
网络要求
- 能够访问镜像仓库:oci://cr.openfuyao.cn。
- 在PD分离场景Mooncake传输KVCache时,若使用HCCL协议跨机高速通信传输,需要有HCCL设备或者RDMA设备支持。
背景信息
无。
使用限制
- 当前仅支持vLLM推理引擎。
- 当前仅支持Mooncake P2P Connector。
- 当前仅在Ascend910B4推理芯片验证。
- 当前仅支持AI推理场景,不支持AI训练场景。
操作步骤
获取服务访问地址。
1.1 查看hermes-router服务的访问地址:
bashkubectl get svc -n ai-inference1.2 记录网关的IP地址与端口。hermes-router服务名称为
inference-gateway-istio。发送推理请求(以curl发送请求为例)。
2.1 发送非流式推理请求:
bashcurl -X POST http://[路由服务IP]:[路由服务端口]/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{ "model": "Qwen/Qwen3-8B", "messages": [{"role": "user", "content": "请介绍openFuyao开源社区"}], "stream": false }'2.2 发送流式推理请求:
bashcurl -X POST http://[路由服务IP]:[路由服务端口]/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{ "model": "Qwen/Qwen3-8B", "messages": [{"role": "user", "content": "请介绍openFuyao开源社区"}], "stream": true }'接收推理结果。
3.1 非流式响应一次性返回完整结果。
3.2 流式响应逐块返回以
data:开头的JSON对象。
相关操作
以release名称infernex和命名空间istio-system为例:
查看部署状态:
helm status infernex -n istio-system卸载系统:
helm uninstall infernex -n istio-system导出配置:
helm get values infernex -n istio-system > current-values.yamlFAQ
hermes-router以及Proxy Server初始阶段有错误信息。
现象描述: 通过查看Pod日志发现最初hermes-router以及Proxy Server有很多报错的请求信息。
处理步骤: 正常现象。hermes-router在初始化完毕后会定期向Proxy Server发送推理引擎指标查询请求,因推理引擎实例初始化时加载大模型耗时较长,此时指标查询请求无法被正确响应。等待推理引擎实例启动完毕后该问题不会出现。
hermes-router以及cache-indexer无法发现推理服务。
现象描述: 通过查看Pod日志发现hermes-router以及cache-indexer自动发现推理服务实例时报错。
处理步骤: 可能因为服务标签选择器配置错误。
hermes-router.app.discovery.labelSelector.app和cache-indexer.app.serviceDiscovery.labelSelector属性代表hermes-router以及cache-indexer对推理后端K8s Service资源的服务发现配置,需要与inference-backend.service.label属性一致。使用helm install -n xxx(非istio-system)安装无法正常工作。
现象描述: 安装完成后,无法找到网关相关的Service资源,或网关无法正常处理流量和请求。
处理步骤: 由于Istio Gateway资源必须部署在
istio-system命名空间中,因此helm安装时必须使用-n istio-system参数指定命名空间。其他组件(如inference-backend、hermes-router、cache-indexer)的命名空间可通过global.namespace配置项进行设置,而Istio相关资源的命名空间由helm的Release.namespace(即-n参数指定的命名空间)确定。正确的安装方式为:helm install -n istio-system infernex ./infernex。部署完成后请求无法正常工作。
现象描述: 安装完成后,Istio Envoy代理报错或无法将请求转发到后端服务,但后端推理服务运行状态正常。
处理步骤: 按以下步骤逐一检查配置:
- 检查
HTTPRoute资源的parentRef.name是否与Gateway资源的名称一致(需与inferenceGateway.name配置项匹配)。 - 检查
HTTPRoute资源的backendRef.name是否与InferencePool资源的名称一致(需与hermes-router.inferencePool.name或global.name配置项匹配)。 - 检查
InferencePool资源的modelServers.matchLabels标签选择器是否与推理服务Pod的标签匹配(需与inference-backend.services[].openfuyao配置项生成的标签一致)。 - 确认路由组件(hermes-router)与推理服务(inference-backend)部署在同一个命名空间下(通过
global.namespace配置项统一设置)。
- 检查
PD分离模式下Decode服务没有正常使用Mooncake进行传输。
现象描述: PD分离架构部署后,Decode推理服务异常或性能不佳。
处理步骤: 检查Decode推理服务的prefix cache配置。在使用Mooncake进行传输的PD分离架构中,Decode推理服务不应启用prefix cache。请确认
pd.decode.enablePrefixCaching配置项设置为false,或使用--no-enable-prefix-caching参数启动Decode服务。PD分离模式下Decode服务一直在计算输出token。
现象描述: 推理引擎使用vllm-ascend v0.11.0rc3版本,配置使用HCCL进行KVCache传输,PD分离架构部署后,Decode节点一直在计算返回token,输出不会停止。
处理步骤: 检查是否挂载宿主机的
hccn.conf文件,以及确认hccn.conf文件内是否对宿主机的推理设备ip以及掩码配置正确。hccn.conf文件配置设备信息可以参考以下脚本:bash#!/bin/bash for i in {0..7} do hccn_tool -i $i -ip -s address 192.168.102.$i netmask 255.255.255.0 done
遵循 木兰宽松许可证第2版(MulanPSL2)
