NPU Operator
Feature Overview
Kubernetes provides access to special hardware resources (such as Ascend NPUs) through Device Plugins. However, multiple software components (such as drivers, container runtimes, or other libraries) are required to configure and manage a node having these hardware resources. Installation of these components is complex, difficult, and error-prone. The NPU operator uses the Operator Framework in Kubernetes to automatically manage all software components required for configuring Ascend devices. These components include the Ascend driver and firmware (which support the entire running process of clusters), as well as the MindCluster device plug-in (which supports cluster operations such as job scheduling, O&M monitoring, and fault recovery). By installing corresponding components, you can manage NPU resources, optimize workload scheduling, and containerize training and inference tasks, so that AI jobs can be deployed and run on NPU devices as containers.
Table 1 Components that can be installed
| Name | Deployment Mode | Function |
|---|---|---|
| Ascend driver and firmware | Containerized deployment managed by the NPU operator | Acts as the bridge between hardware devices and the operating system (OS), enabling the OS to recognize and communicate with the hardware. |
| Ascend Device Plugin | Containerized deployment managed by the NPU operator | Enables device discovery, device allocation, and device health status reporting of Ascend AI processors based on Kubernetes' device plug-in mechanism, so that Kubernetes can manage Ascend AI processor resources. |
| Ascend Operator | Containerized deployment managed by the NPU operator | Environment configuration: Serves as a Volcano-supporting component that manages acjob tasks and injects environment variables required for training tasks in the AI framework (MindSpore, PyTorch, or TensorFlow) into containers, which are then scheduled by Volcano. |
| Ascend Docker Runtime | Containerized deployment managed by the NPU operator | Ascend container runtime: Serves as a container engine plug-in that provides NPU-based containerization support for all AI jobs so that AI jobs can run smoothly on Ascend devices as Docker containers. |
| NPU Exporter | Containerized deployment managed by the NPU operator | Real-time monitoring of Ascend AI processor resource data: Collects resource data of Ascend AI processors in real time, including the processor usage, temperature, voltage, and memory usage. In addition, it can monitor the virtual NPUs (vNPUs) of Atlas inference series products, including key indicators such as the AI Core usage, total memory of the vNPUs, and used memory. |
| Resilience Controller | Containerized deployment managed by the NPU operator | Dynamic scaling: Removes the faulty resources and continues the training with reduced specifications if a fault occurs during task training and no sufficient healthy resources are available for replacement, and restores the training tasks with the same specifications as the original tasks after the resources are sufficient. |
| ClusterD | Containerized deployment managed by the NPU operator | Collects task, resource, and fault information of clusters, determines the fault handling level and policy in a unified manner, and controls the process recalculation of the training containers. |
| Volcano | Containerized deployment managed by the NPU operator | Obtains resource information about a cluster from underlying components and selects the optimal scheduling policy and resource allocation based on the network connection mode between Ascend chips. Reschedules the task in case of failures of resources allocated to a task. |
| NodeD | Containerized deployment managed by the NPU operator | Detects the resource monitoring status and fault information of nodes, reports the fault information, and prevents new tasks from being scheduled to faulty nodes. |
| MindIO | Containerized deployment managed by the NPU operator | Generates and saves an end-of-life checkpoint after a model training interruption, rectifies UCE faults in the on-chip memory online during model training, provides the capability of restarting or replacing nodes to rectify faults and resume model training, and optimizes checkpoint saving and loading. |
For details about the component, see MindCluster Introduction.
Mapping between hardware and versions
| Component | Version |
|---|---|
| Ascend driver and firmware | 24.1.RC3 |
| Ascend Device Plugin | 6.0.0 |
| Ascend Operator | 6.0.0 |
| Ascend Docker Runtime | 6.0.0 |
| NPU Exporter | 6.0.0 |
| Resilience Controller | 6.0.0 |
| ClusterD | 6.0.0 |
| Volcano | 6.0.0 (based on the original Volcano 1.9.0) |
| NodeD | 6.0.0 |
| MindIO | 6.0.0 |
Application Scenarios
In scenarios where a cluster is built based on Ascend devices and job scheduling, O&M monitoring, and fault recovery are required, the NPU operator can be used to automatically identify Ascend nodes in the cluster and perform component installation and deployment. In training scenarios, the NPU operator supports resource detection, full NPU scheduling, static vNPU scheduling, resumable training, and elastic training. In inference scenarios, the NPU operator supports resource detection, full NPU scheduling, static vNPU scheduling, dynamic vNPU scheduling, inference card fault recovery, and rescheduling.
Supported Capabilities
- Automatically discovers nodes equipped with Ascend NPUs and labels them.
- Automatically deploys the Ascend NPU driver and firmware.
- Supports automated deployment, installation, and lifecycle management of the cluster scheduling component in a MindCluster.
Highlights
The NPU operator can automatically identify Ascend nodes and device models in a cluster and install the required version of AI runtime components, significantly reducing the complexity of configuring the Ascend ecosystem. It provides automated component deployment and full lifecycle management of installed components. The NPU operator is also able to monitor the installation status of components and generate detailed logs for debugging.
Implementation Principles
- The NPU operator can monitor changes of custom resources (CRs) instantiated from custom resource definitions (CRDs) and update the state of managed components accordingly.
- Based on the labels marked by the Node Feature Discovery (NFD) service on nodes, the NPU operator uses the Npu-Feature-Discovery component to mark nodes with labels that match the scheduling requirements of Ascend components.
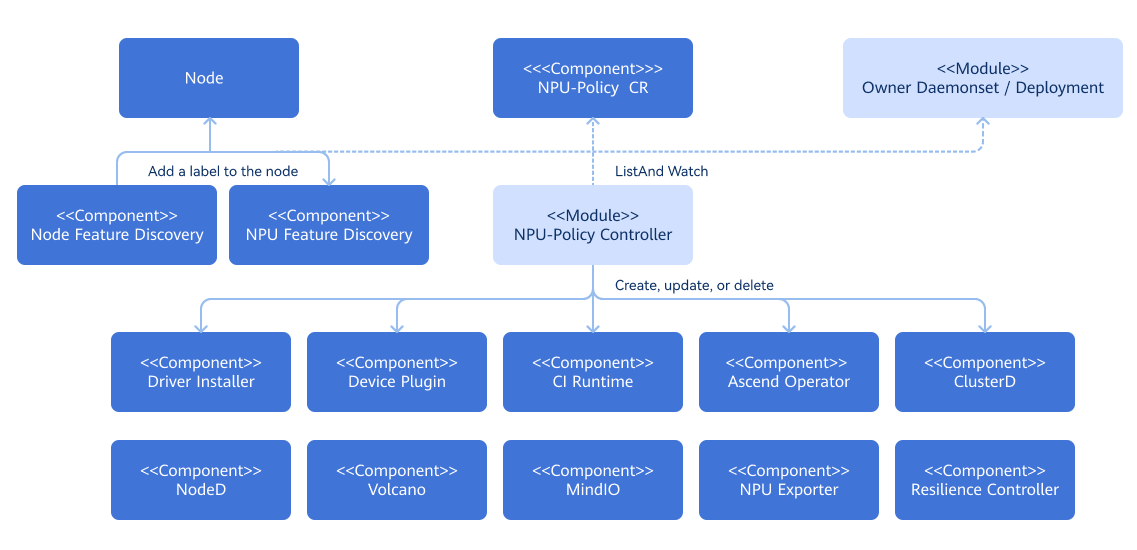
Relationship with Related Features
Ensure that application-management-service and marketplace-service are running properly so that this feature can be properly installed from the application market.
Security Context of the Operator
Certain pods (for example, driver containers) managed by the NPU operator require elevated privileges as follows:
privileged: truehostPID: truehostIPC: truehostNetwork: true
The reasons for elevating privileges are as follows:
- To access the file system and hardware devices of the host and install driver, firmware, and SDK service on the host
- To modify device permissions to enable usage by non-root users
Installation
Deployment on the openFuyao platform
Online Installation
Prerequisites
-
Ensure that kubectl and Helm CLI are installed on your host, or that a configurable application store or repository is available in the cluster.
-
Ensure that the bash tool exists in the environment. Otherwise, the driver and firmware installation script may fail to be parsed.
-
All worker nodes or node groups running NPU workloads in a Kubernetes cluster must operate in the openEuler 22.03 LTS or Ubuntu 22.04 OS(Arm architecture).
Worker node or node groups that run CPU workloads only may operate in any OS because the NPU operator does not perform any configuration or management operation on a node that is not dedicated to NPU workloads.
The runtime environment of the components installed by the NPU operator must use Ascend 910B or Ascend 310P NPU chips. For details on the OS and hardware compatibility mapping, see MindCluster Documentation.
-
Node-Feature-Discovery and NPU-Feature-Discovery are dependencies for the operator on each node.
 NOTE
NOTE
By default, the NFD master node and worker nodes are automatically deployed by the operator. If the NFD is already running in the cluster, its deployment must be disabled during operator installation. Similarly, if NPU-Feature-Discovery has been deployed in the cluster in advance, you need to disable the deployment of NPU-Feature-Discovery during operator installation.values.yaml
nfd:
enabled: false
npu-feature-discovery:
enabled: falseCheck the NFD label on the nodes to determine whether the NFD is running in the cluster.
kubectl get nodes -o json | jq '.items[].metadata.labels | keys | any(startswith("feature.node.kubernetes.io"))'If the command output is
true, the NFD is already running in the cluster. In this case, configurenodefeaturerulesto install the custom NPU node discovery rules.nfd:
nodefeaturerules: trueBy default, nfd is set true, npu-feature-discovery is set to true, and nodefeaturerules is set to false.
Procedure
Download the NPU operator extension from the openFuyao application market and install it.
- Log in to the openFuyao platform. In the left navigation pane, choose Application Market > Applications.
- Search for npu-operator in the application list and find the NPU operator extension.
- Click the NPU Operator card. The application details page is displayed.
- On the details page, click Deploy in the upper right corner. In the Installation Information area on the deployment page, set Application name, Version, and Namespace.
- Click OK.
Offline Installation
Prerequisites
- For details, see Prerequisites for Online Installation.
- Downloading offline images: Download all images required to install components to your local PC.
- Prepare the driver and firmware package and the MindIO SDK package.
- Download the packages. For the driver and firmware package, find the config.json file in the GitCode repository of the npu-driver-installer, and download the package based on the NPU model and OS architecture of the corresponding node through the corresponding link provided. For the MindIO SDK package, find the config.json file in the GitCode repository of the npu-node-provision, and download the SDK package based on the NPU model and OS architecture of the corresponding node through the corresponding link provided.
- Save the ZIP file of the driver and firmware package to the
/opt/openFuyao-npu-driver/npu-driver/*NPU model*/path of the node where the offline installation is to be performed. For example, if the node uses the Ascend 310P NPU, the storage path is/opt/openFuyao-npu-driver/npu-driver/310p/. - Save the ZIP file of the MindIO package to the
/opt/openFuyao/mindio/path of the node where the offline installation is to be performed. - Check whether the target node contains the following tools.
- For systems using Yum as the package manager, the following package needs to be installed: "jq wget unzip which initscripts coreutils findutils gawk e2fsprogs util-linux net-tools pciutils gcc make automake autoconf libtool git patch kernel-devel- ( u n a m e - r ) k e r n e l - h e a d e r s - (uname-r)kernel-headers- (uname -r) dkms".
- For systems using apt-get as the package manager, the following package needs to be installed: "jq wget unzip debianutils coreutils findutils gawk e2fsprogs util-linux net-tools pciutils gcc make automake autoconf libtool git patch dkms linux-headers-$(uname -r)".
- For systems using DNF as the package manager, the following package needs to be installed: "jq wget unzip which initscripts coreutils findutils gawk e2fsprogs util-linux net-tools pciutils gcc make automake autoconf libtool git patch kernel-devel-$(uname -r) kernel-headers-$(uname -r) dkms".
Procedure
For details, see Online Installation Procedure.
Standalone Deployment
Online Installation
Prerequisites
For details, see Prerequisites for Deploying the openFuyao Platform.
Procedure
-
Add an openFuyao Helm repository.
helm repo add openfuyao https://helm.openfuyao.cn && helm repo update -
Install the NPU operator.
-
Install the operator using the default configurations.
helm install --wait --generate-name \
-n default --create-namespace \
openfuyao/npu-operator
If the operator is installed using the Helm application store or application market, add the repository at https://helm.openfuyao.cn and install it on the user interface (UI). For details, see Common Customization Options.
- After the NPU operator is installed, it automatically applies NPU resource–related labels to nodes based on their environments. These labels are associated with cluster scheduling components. Among them, the accelerate-type label requires an exact match between the node's hardware server and the NPU card. For details about the compatibility mapping, see Creating a Node Label in the MindCluster documentation.
- For the A800I A2 inference server, the server-usage=infer label cannot be automatically added. You need to run the following command to manually add the label:
kubectl label nodes <*Node name*> server-usage=infer
Common Customization Options
The following options are available when you use the Helm chart. These options can be used with --set when you install the operator using Helm.
Table 2 lists the most commonly used options.
| Option | Description | Default Value |
|---|---|---|
nfd.enabled | Whether to deploy the NFD service. If the NFD service is already running in the cluster, set this parameter to false.
| true |
nfd.nodefeaturerules | If this parameter is set to true, a CR containing a rule is installed. This rule enables NFD to discover NPU devices. | true |
node-feature-discovery.image.repository | Image path of the NFD service. | registry.k8s.io/nfd/node-feature-discovery |
node-feature-discovery.image.pullPolicy | Image pulling policy of the NFD service. | Always |
node-feature-discovery.image.tag | Image version of the NFD service. | v0.16.4 |
npu-feature-discovery.image.repository | Image path of the NPU-Feature-Discovery component. | cr.openfuyao.cn/openfuyao/npu-feature-discovery |
npu-feature-discovery.image.pullPolicy | Image pulling policy of the NPU-Feature-Discovery component. | latest |
npu-feature-discovery.image.tag | Image version of the NPU-Feature-Discovery component. | Always |
npu-feature-discovery.enabled | Whether to deploy the NPU-Feature-Discovery component. If the NPU-Feature-Discovery component is already running in the cluster, set this parameter to false. | true |
operator.image | Image path of the NPU operator. | cr.openfuyao.cn/openfuyao/npu-operator |
operator.version | Image version of the NPU operator. | latest |
operator.imagePullPolicy | Image pulling policy of the NPU operator. | IfNotPresent |
daemonSets.labels | Custom labels to be added to all pods managed by the NPU operator. | {} |
daemonSets.tolerations | Custom tolerance to be added to all pods managed by the NPU operator. | [] |
driver.enabled | By default, the operator deploys the NPU driver and firmware on the system as a container. | true |
driver.registry | Image repository of the driver and firmware. Specify another image repository if using a custom driver image. | cr.openfuyao.cn |
driver.repository | Image path of the driver and firmware. | openfuyao/ascend-image/ascend-operator |
driver.tag | Image version of the driver and firmware installation service. | v6.0.0 |
driver.version | Version of the driver and firmware. | 24.1.RC3 |
devicePlugin.enabled | Whether the operator deploys the NPU device plug-in on the system. By default, the operator deploys the NPU device plug-in on the system. When using the operator on a system where the device plug-in is pre-installed, set this parameter to false.
| true |
devicePlugin.registry | Image repository of the device plug-in. | cr.openfuyao.cn |
devicePlugin.repository | Image path of the device plug-in. | openfuyao/ascend-image/ascend-k8sdeviceplugin |
devicePlugin.tag | Image version of the device plug-in. | v6.0.0 |
trainer.enabled | Whether the operator installs the Ascend operator. By default, the operator installs the Ascend operator. If the Ascend operator is not required, set this parameter to false. | true |
trainer.registry | Image repository of the Ascend operator. Specify another image repository if using a custom driver image. | cr.openfuyao.cn |
trainer.repository | Image path of the Ascend operator. | openfuyao/ascend-image/ascend-operator |
trainer.tag | Image version of the Ascend operator. | v6.0.0 |
ociRuntime.enabled | Whether the operator installs the Ascend Docker Runtime. By default, the operator installs the Ascend Docker Runtime. If the Ascend Docker Runtime is not required, set this parameter to false. | true |
ociRuntime.registry | Image repository of the Ascend Docker Runtime. Specify another image repository if using a custom image. | cr.openfuyao.cn |
ociRuntime.repository | Image path of the Ascend Docker Runtime. | openfuyao/npu-container-toolkit |
ociRuntime.tag | Image version of the Ascend Docker Runtime. | latest |
nodeD.enabled | Whether the operator installs the nodeD. By default, the operator installs the nodeD. If the nodeD is not required, set this parameter to false. | true |
ndoeD.registry | Image repository of the nodeD. Specify another image repository if using a custom image. | cr.openfuyao.cn |
nodeD.repository | Image path of the nodeD. | openfuyao/ascend-image/nodeD |
nodeD.tag | Image version of the nodeD. | v6.0.0 |
clusterd.enabled | Whether the operator installs the clusterD. By default, the operator installs the clusterD. If the clusterD is not required, set this parameter to false. | true |
clusterd.registry | Image repository of the clusterD. Specify another image repository if using a custom image. | cr.openfuyao.cn |
clusterd.repository | Image path of the clusterD. | openfuyao/ascend-image/clusterd |
clusterd.tag | Image version of the clusterD. | v6.0.0 |
rscontroller.enabled | Whether the operator installs the resilience controller component. By default, the operator installs the resilience controller component. If the resilience controller component is not required, set this parameter to false. | true |
rscontroller.registry | Image repository of the resilience controller component. Specify another image repository if using a custom image. | cr.openfuyao.cn |
rscontroller.repository | Image path of the resilience controller component. | openfuyao/ascend-image/resilience-controller |
rscontroller.tag | Image version of the resilience controller component. | v6.0.0 |
exporter.enabled | Whether the operator installs the NPU Exporter component. By default, the operator installs the NPU Exporter component. If the NPU Exporter component is not required, set this parameter to false. | true |
exporter.registry | Image repository of the NPU Exporter component. Specify another image repository if using a custom image. | cr.openfuyao.cn |
exporter.repository | Image path of the NPU Exporter component. | openfuyao/ascend-image/npu-exporter |
exporter.tag | Image version of the NPU Exporter component. | v6.0.0 |
mindiotft.enabled | Whether the operator installs the MindIO Training Fault Tolerance (TFT). By default, the operator installs the MindIO TFT. If the MindIO TFT is not required, set this parameter to false. | true |
mindiotft.registry | Image repository of the MindIO TFT. Specify another image repository if using a custom image. | cr.openfuyao.cn |
mindiotft.repository | Image path of the MindIO TFT. | openfuyao/npu-node-provision |
mindiotft.tag | Image version of the MindIO TFT. | latest |
mindioacp.enabled | Whether the operator installs the MindIO ACP (ACP) component. By default, the operator installs the MindIO ACP component. If the MindIO ACP component is not required, set this parameter to false. | true |
mindioacp.registry | Image repository of the MindIO ACP component. Specify another image repository if using a custom image. | cr.openfuyao.cn |
mindioacp.repository | Image path of the MindIO ACP component. | openfuyao/npu-node-provision |
mindioacp.tag | Image version of the MindIO ACP component. | latest |
mindioacp.version | MindIO ACP version component. | 6.0.0 |
Offline Installation
Prerequisites
For details, see Prerequisites for Deploying the openFuyao Platform.
Procedure
-
Prepare the chart package of the NPU operator.
-
Install the operator using the default configurations.
cd npu-operator/charts
helm install <npu-operator release name> npu-operatorFor details about common customization options, see Table 2.
Upgrade
The NPU operator supports dynamic updates to existing resources. This ensures that NPU policy settings in the cluster are always kept up to date.
Because Helm does not support automatic upgrades of existing CRDs, the NPU operator chart can be upgraded either manually or by enabling the Helm hook.
Updating the CRs for the NPU Policy
The NPU operator supports dynamic updates to the npuclusterpolicy CR through kubectl.
kubectl get npuclusterpolicy -A
# # If the default settings of **npuclusterpolicy** are not modified, the default name of **npuclusterpolicy** is **cluster**.
kubectl edit npuclusterpolicy cluster
After the editing is complete, Kubernetes automatically updates the application to the cluster. The components managed by the NPU operator are also updated to their expected statuses.
Verifying the Installation Status
Viewing Component Status Through the CR
You can use the npuclusterpolicies.npu.openfuyao.com CR to check the status of components. Specifically, check the state field of each component in the status field to determine the current status of the component. The following is an example of the status when the driver installer is running properly.
status:
componentStatuses:
- name: /var/lib/npu-operator/components/driver
prevState:
reason: Reconciling
type: deploying
state:
reason: Reconciled
type: running
- View the CR.
$ kubectl get npuclusterpolicies.npu.openfuyao.com cluster -o yaml
apiVersion: npu.openfuyao.com/v1
kind: NPUClusterPolicy
metadata:
annotations:
meta.helm.sh/release-name: npu
meta.helm.sh/release-namespace: default
creationTimestamp: "2025-03-11T13:22:39Z"
generation: 2
labels:
app.kubernetes.io/managed-by: Helm
app.kubernetes.io/name: npu-operator
name: cluster
resourceVersion: "2240086"
uid: 0d1498c5-143a-4e05-a5dc-376d2e6c96ea
spec:
clusterd:
imageSpec:
imagePullPolicy: Always
imagePullSecrets: []
registry: cr.openfuyao.cn
repository: openfuyao/ascend-image/clusterd
tag: v6.0.0
logRotate:
compress: false
logFile: /var/log/mindx-dl/clusterd/clusterd.log
logLevel: info
maxAge: 7
rotate: 30
managed: true
daemonsets:
imageSpec:
imagePullPolicy: IfNotPresent
imagePullSecrets: []
labels:
app.kubernetes.io/managed-by: npu-operator
helm.sh/chart: npu-operator-0.0.0-latest
tolerations:
- effect: NoSchedule
key: node-role.kubernetes.io/master
operator: Equal
value: ""
- effect: NoSchedule
key: node-role.kubernetes.io/control-plane
operator: Equal
value: ""
devicePlugin:
imageSpec:
imagePullPolicy: Always
imagePullSecrets: []
registry: cr.openfuyao.cn
repository: openfuyao/ascend-image/ascend-k8sdeviceplugin
tag: v6.0.0
initImageSpec:
imagePullPolicy: Always
imagePullSecrets: []
registry: ""
repository: hub.oepkgs.net/busybox:latest
tag: ""
logRotate:
compress: false
logFile: /var/log/mindx-dl/devicePlugin/devicePlugin.log
logLevel: info
maxAge: 7
rotate: 30
managed: true
driver:
imageSpec:
imagePullPolicy: Always
imagePullSecrets: []
registry: cr.openfuyao.cn
repository: openfuyao/npu-driver-installer
tag: latest
initImageSpec:
imagePullPolicy: Always
imagePullSecrets: []
registry: ""
repository: cr.openfuyao.cn/openfuyao/npu-driver-installer:latest
tag: ""
logRotate:
compress: false
logFile: /var/log/mindx-dl/driver/driver.log
logLevel: info
maxAge: 7
rotate: 30
managed: true
version: 24.1.RC3
exporter:
imageSpec:
imagePullPolicy: Always
imagePullSecrets: []
registry: cr.openfuyao.cn
repository: openfuyao/ascend-image/npu-exporter
tag: v6.0.0
logRotate:
compress: false
logFile: /var/log/mindx-dl/npu-exporter/npu-exporter.log
logLevel: info
maxAge: 7
rotate: 30
managed: true
mindioacp:
imageSpec:
imagePullPolicy: Always
imagePullSecrets: []
registry: cr.openfuyao.cn
repository: openfuyao/npu-node-provision
tag: latest
managed: false
version: 6.0.0
mindiotft:
imageSpec:
imagePullPolicy: Always
imagePullSecrets: []
registry: cr.openfuyao.cn
repository: openfuyao/npu-node-provision
tag: latest
managed: false
nodeD:
heartbeatInterval: 5
imageSpec:
imagePullPolicy: Always
imagePullSecrets: []
registry: cr.openfuyao.cn
repository: openfuyao/ascend-image/noded
tag: v6.0.0
logRotate:
compress: false
logFile: /var/log/mindx-dl/noded/noded.log
logLevel: info
maxAge: 7
rotate: 30
managed: true
pollInterval: 60
ociRuntime:
imageSpec:
imagePullPolicy: Always
imagePullSecrets: []
registry: cr.openfuyao.cn
repository: openfuyao/npu-container-toolkit
tag: latest
initConfigImageSpec:
imagePullPolicy: Always
imagePullSecrets: []
registry: ""
repository: cr.openfuyao.cn/openfuyao/npu-container-toolkit:latest
tag: ""
initRuntimeImageSpec:
imagePullPolicy: Always
imagePullSecrets: []
registry: ""
repository: cr.openfuyao.cn/openfuyao/ascend-image/ascend-docker-runtime:latest
tag: ""
interval: 300
managed: true
operator:
imageSpec:
imagePullPolicy: IfNotPresent
imagePullSecrets: []
runtimeClass: ascend
rscontroller:
imageSpec:
imagePullPolicy: Always
imagePullSecrets: []
registry: cr.openfuyao.cn
repository: openfuyao/ascend-image/resilience-controller
tag: v6.0.0
logRotate:
compress: false
logFile: /var/log/mindx-dl/resilience-controller/run.log
logLevel: info
maxAge: 7
rotate: 30
managed: true
trainer:
imageSpec:
imagePullPolicy: Always
imagePullSecrets: []
registry: cr.openfuyao.cn
repository: openfuyao/ascend-image/ascend-operator
tag: v6.0.0
initImageSpec:
imagePullPolicy: Always
imagePullSecrets: []
registry: ""
repository: hub.oepkgs.net/library/busybox:latest
tag: ""
logRotate:
compress: false
logFile: /var/log/mindx-dl/ascend-operator/ascend-operator.log
logLevel: info
maxAge: 7
rotate: 30
managed: true
vccontroller:
controllerResources:
limits:
cpu: 1000m
memory: 1Gi
requests:
cpu: 1000m
memory: 1Gi
imageSpec:
imagePullPolicy: Always
imagePullSecrets: []
registry: cr.openfuyao.cn
repository: openfuyao/ascend-image/vc-controller-manager
tag: v1.9.0-v6.0.0
managed: true
vcscheduler:
imageSpec:
imagePullPolicy: Always
imagePullSecrets: []
registry: cr.openfuyao.cn
repository: openfuyao/ascend-image/vc-scheduler
tag: v1.9.0-v6.0.0
managed: true
schedulerResources:
limits:
cpu: 200m
memory: 1Gi
requests:
cpu: 200m
memory: 1Gi
status:
componentStatuses:
- name: /var/lib/npu-operator/components/driver
prevState:
reason: Reconciling
type: deploying
state:
reason: Reconciled
type: running
- name: /var/lib/npu-operator/components/oci-runtime
prevState:
reason: Reconciling
type: deploying
state:
reason: Reconciled
type: running
- name: /var/lib/npu-operator/components/device-plugin
prevState:
reason: Reconciling
type: deploying
state:
reason: Reconciled
type: running
- name: /var/lib/npu-operator/components/trainer
prevState:
reason: Reconciling
type: deploying
state:
reason: Reconciled
type: running
- name: /var/lib/npu-operator/components/noded
prevState:
reason: Reconciling
type: deploying
state:
reason: Reconciled
type: running
- name: /var/lib/npu-operator/components/volcano/volcano-controller
prevState:
reason: Reconciling
type: deploying
state:
reason: Reconciled
type: running
- name: /var/lib/npu-operator/components/volcano/volcano-scheduler
prevState:
reason: Reconciling
type: deploying
state:
reason: Reconciled
type: running
- name: /var/lib/npu-operator/components/clusterd
prevState:
reason: Reconciling
type: deploying
state:
reason: Reconciled
type: running
- name: /var/lib/npu-operator/components/resilience-controller
prevState:
reason: Reconciling
type: deploying
state:
reason: Reconciled
type: running
- name: /var/lib/npu-operator/components/npu-exporter
prevState:
reason: Reconciling
type: deploying
state:
reason: Reconciled
type: running
- name: /var/lib/npu-operator/components/mindio/mindiotft
prevState:
reason: Reconciling
type: deploying
state:
reason: ComponentUnmanaged
type: unmanaged
- name: /var/lib/npu-operator/components/mindio/mindioacp
prevState:
reason: Reconciling
type: deploying
state:
reason: ComponentUnmanaged
type: unmanaged
conditions:
- lastTransitionTime: "2025-03-11T13:25:41Z"
message: ""
reason: Ready
status: "False"
type: Error
- lastTransitionTime: "2025-03-11T13:25:41Z"
message: all components have been successfully reconciled
reason: Reconciled
status: "True"
type: Ready
namespace: default
phase: Ready
Manually Checking the Installation Status and Running Result of Each Component
-
Checking the Driver Installation Status
Run the
npu-smi infocommand to check the driver installation. If information similar to the following is displayed, the driver has been installed.
+------------------------------------------------------------------------------------------------+
| npu-smi 24.1.rc2 Version: 24.1.rc2 |
+---------------------------+---------------+----------------------------------------------------+
| NPU Name | Health | Power(W) Temp(C) Hugepages-Usage(page)|
| Chip | Bus-Id | AICore(%) Memory-Usage(MB) HBM-Usage(MB) |
+===========================+===============+====================================================+
| 0 910B3 | OK | 99.1 55 0 / 0 |
| 0 | 0000:C1:00.0 | 0 0 / 0 3162 / 65536 |
+===========================+===============+====================================================+
| 1 910B3 | OK | 91.7 53 0 / 0 |
| 0 | 0000:C2:00.0 | 0 0 / 0 3162 / 65536 |
+===========================+===============+====================================================+
| 2 910B3 | OK | 98.2 51 0 / 0 |
| 0 | 0000:81:00.0 | 0 0 / 0 3162 / 65536 |
+===========================+===============+====================================================+
| 3 910B3 | OK | 93.2 49 0 / 0 |
| 0 | 0000:82:00.0 | 0 0 / 0 3162 / 65536 |
+===========================+===============+====================================================+
| 4 910B3 | OK | 98.8 55 0 / 0 |
| 0 | 0000:01:00.0 | 0 0 / 0 3163 / 65536 |
+===========================+===============+====================================================+
| 5 910B3 | OK | 96.2 56 0 / 0 |
| 0 | 0000:02:00.0 | 0 0 / 0 3163 / 65536 |
+===========================+===============+====================================================+
| 6 910B3 | OK | 96.9 53 0 / 0 |
| 0 | 0000:41:00.0 | 0 0 / 0 3162 / 65536 |
+===========================+===============+====================================================+
| 7 910B3 | OK | 97.6 55 0 / 0 |
| 0 | 0000:42:00.0 | 0 0 / 0 3163 / 65536 |
+===========================+===============+====================================================+
+---------------------------+---------------+----------------------------------------------------+
| NPU Chip | Process id | Process name | Process memory(MB) |
+===========================+===============+====================================================+
| No running processes found in NPU 0 |
+===========================+===============+====================================================+
| No running processes found in NPU 1 |
+===========================+===============+====================================================+
| No running processes found in NPU 2 |
+===========================+===============+====================================================+
| No running processes found in NPU 3 |
+===========================+===============+====================================================+
| No running processes found in NPU 4 |
+===========================+===============+====================================================+
| No running processes found in NPU 5 |
+===========================+===============+====================================================+
| No running processes found in NPU 6 |
+===========================+===============+====================================================+
| No running processes found in NPU 7 |
+===========================+===============+====================================================+ -
Checking the Installation Status of the MindCluster Components
Run the
kubectl get pod -Acommand to check all pods. If all pods are in the running state, the components are started successfully. For details about how to verify the status of each component, see MindCluster Official Documentation.
NAMESPACE NAME READY STATUS RESTARTS AGE
default ascend-runtime-containerd-7lg85 1/1 Running 0 6m31s
default npu-driver-c4744 1/1 Running 0 6m31s
default npu-operator-77f56c9f6c-fhx8m 1/1 Running 0 6m32s
default npu-feature-discovery-zqgt9 1/1 Running 0 7m12s
default mindio-acp-43f64g63d2v 1/1 Running 0 7m21s
default mindio-tft-2cc35gs3c2u 1/1 Running 0 6m32s
kube-system ascend-device-plugin-fm4h9 1/1 Running 0 6m35s
mindx-dl ascend-operator-manager-6ff7468bd9-47d7s 1/1 Running 0 6m50s
mindx-dl clusterd-5ffb8f6787-n5m82 1/1 Running 0 6m48s
mindx-dl noded-kmv8d 1/1 Running 0 7m11s
mindx-dl resilience-controller-6727f36c28-wjn3s 1/1 Running 0 7m20s
npu-exporter npu-exporter-b6txl 1/1 Running 0 7m22s
volcano-system volcano-controllers-373749bg23c-mc9cq 1/1 Running 0 7m31s
volcano-system volcano-scheduler-d585db88f-nkxch 1/1 Running 0 7m40s
Uninstallation
To uninstall the operator, perform the following steps:
-
Run the following command to remove the operator through the Helm CLI or application management page:
helm delete <npu-operator release name>
By default, Helm does not delete existing CRDs when deleting a chart.
kubectl get crd npuclusterpolicies.npu.openfuyao.com
- Remove the CRDs manually by running the following command:
kubectl delete crd npuclusterpolicies.npu.openfuyao.com
After the operator is uninstalled, the driver may still exist on the host machine.
Remarks on Component Installation and Uninstallation
Installation and Uninstallation Fields for Each Component
-
During the first installation of the NPU operator, if the enabled field of the corresponding component in values.yaml is set to
true, the component resources, regardless of whether they already exist in the cluster, will be replaced with the resources managed by the NPU operator. -
If a component (for example, volcano-controller) already exists in the cluster and the
enabledfield of the component in values.yaml is set tofalseduring the first installation of the NPU operator, the existing component resources in the cluster will not be removed. -
After the NPU operator is installed, you can modify the corresponding fields of the CR instance to manage the image path, resource configuration, and lifecycle of the corresponding component.
MindIO Installation Dependencies
-
To install MindIO components, the Python environment must be pre-installed on the node (with the pip3 tool available). Supported Python versions are 3.7 through 3.11. Without the required environment, the installation will fail. When using MindIO, you can mount the installed SDK to the training container.
-
The installation path for the MindIO TFT component is /opt/sdk/tft. Prebuilt WHL packages for different Python versions are provided in /opt/tft-whl-package to meet customization requirements. For details, see section "Fault Recovery Acceleration" in MindCluster Documentation.
-
The installation paths for the MindIO ACP component are /opt/mindio and /opt/sdk/acp. Prebuilt WHL packages for different Python versions are provided in /opt/acp-whl-package. You can install the component using the corresponding package as required. For details, see section "Checkpoint Saving and Loading Optimization" in MindCluster Documentation.
-
When a MindIO component is uninstalled, the SDK folder and other folders related to the MindIO component will be removed. This may cause the task container that uses the service to operate abnormally. Proceed with caution.